Developer
Una installazione npm. Esegui in locale con un motore incluso: le righe estratte non lasciano mai la macchina.
Il motore di dati web che il tuo team può eseguire da laptop, pipeline CI o dentro l agente AI che lancerai presto: stesso binario, stesso contratto.
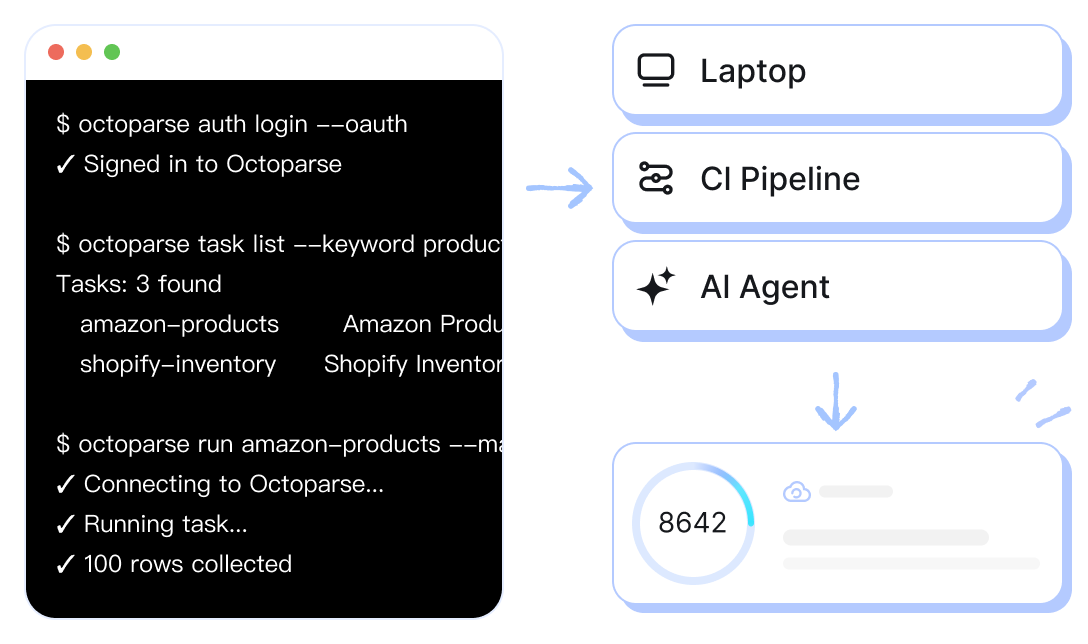
Stessa CLI. Stessi codici di uscita. Stesso contratto JSON, che venga eseguita su laptop, in CI o dentro un loop di agenti.
Una installazione npm. Esegui in locale con un motore incluso: le righe estratte non lasciano mai la macchina.
Inseriscila in GitHub Actions, Docker, Airflow o cron. Codici di uscita stabili e autenticazione via variabili ambiente che non tocca mai il disco: supera la revisione sicurezza al primo giro.
Passa la CLI a Claude, Cursor o al tuo loop di agenti. Lo streaming JSONL permette all agente di pianificare il passo successivo prima della fine della run.
Lo stesso binario sul laptop, nella pipeline CI o dentro un agente: abbastanza prevedibile da entrare nella rotazione di reperibilità.
Un growth analyst estrae ogni mattina prezzi concorrenti in un notebook Jupyter. Una run + un export dati: foglio fresco prima del caffè, senza dover sorvegliare Selenium.
$ octoparse run lp-pricing
✓ 248 rows → pricing.csv
Un team dati retail esegue estrazioni programmate in CI ogni lunedì alle 06:00 UTC. Codici di uscita stabili instradano i successi a valle e i fallimenti alla reperibilità: zero container da mantenere.
# .github/workflows/pull.yml
- run: octoparse run $TASK --json
- run: dbt build
Una startup vertical-AI espone la CLI dentro Claude / Cursor come tool strutturato. Lo streaming JSONL fornisce feedback riga per riga, così l agente può pianificare il passo successivo prima della fine della run.
tool: octoparse.run
stream: jsonl
next_action: enrich rows
Sei ragioni per cui i clienti scelgono Octoparse e restano.
Oltre 200 template pronti all'esecuzione: Amazon, LinkedIn, Google Maps, YouTube, Yelp, HN, Reddit e altro ancora. Una struttura REST, gli stessi campi canonici, senza manutenzione di XPath o selettori.
Pool di browser, rotazione proxy, anti-bot, paginazione, export strutturato: testato sul campo dal 2018.
Le tue run, i tuoi byte. Non rivendiamo, non redistribuiamo e non addestriamo modelli sui dati che estraiamo per te. Imposta una finestra di conservazione, premi elimina ed è fatto. Ogni run riceve un trace_id che puoi verificare o rieseguire.
JSON, JSONL, CSV, XLSX, XML: la stessa forma canonica. Invia direttamente a Snowflake tramite Airbyte, dbt, Airflow o il tuo ETL.
Funziona nativamente con Claude, GPT, Cursor, Cline, Dify e LangChain. Lo streaming JSONL permette al tuo agente di pianificare il passo successivo prima della fine della run.
Prova gratuita, senza carta di credito. Prezzi trasparenti a consumo in seguito. I team segnalano di sostituire stack interni di scraping a 1/18 del costo del personale.
Costruito su otto anni di infrastruttura di scraping e sul feedback di team che lo eseguono già in produzione.
"Siamo passati da una flotta Selenium su tre istanze EC2 a una singola invocazione CLI in GitHub Actions."
"Il nostro loop di agenti la chiama come tool. Lo streaming JSONL consente di pianificare il passo successivo prima della fine. Un grande passo avanti per la UX."
"Codici di uscita stabili, auth tramite variabili ambiente: ha superato la nostra revisione sicurezza al primo giro. Con gli strumenti di scraping succede raramente."
A supporto dei team dati e AI presso
Ritira lo scraper. Tieni i dati
Prova gratuita. Nessuna carta di credito. La maggior parte dei team lo esegue in CI prima dello standup quotidiano.