Estrarre il testo da un file HTML è letteralmente la stessa cosa che copiare e incollare le informazioni di una pagina web su un blocco note. Può sembrare semplice, ma immagina se dovessi estrarre testo da migliaia di file HTML (pagine web), allora non sarebbe così divertente. In realtà, estrarre testo dalle pagine web serve a molteplici utilizzi pratici, per citarne alcuni:
- Scaricare i blog dalle pagine web
- Scaricare tutti gli articoli di notizie da un sito web specifico
- Estrapolare informazioni sui prodotti come SKU, modello e descrizione da siti di eCommerce come Amazon ed eBay.
- Estrarre solo la parte testuale della pagina web, senza tabelle, immagini o altri tipi di dati
- Pulire un file HTML disordinato per includere solo il contenuto leggibile dal file
Esplorando la Struttura dei File HTML
Per qualsiasi motivo tu abbia bisogno di estrarre testo da un file HTML, è utile sapere un po’ su come il testo o diversi tipi di dati sono incorporati in un file HTML prima di mettersi al lavoro.
Il componente principale di un file HTML è un array di elementi all’interno dei quali sono incorporati tutti i tipi di dati, inclusi i testi. Questi elementi sono disposti in un certo modo per formare la struttura di una pagina web.
Questo è un esempio tratto da uno degli esercizi HTML di W3School:
<p>
Questo paragrafo
contiene molte righe
nel codice sorgente,
ma il browser
lo ignora.
</p>
Puoi vedere quanto sopra come un elemento. <p> e </p> sono i tag (il primo segna un inizio e il secondo una fine). Il testo è spesso racchiuso tra tag come <p>, <span>, <h>, ecc.
Comprendere la struttura di un file HTML sarebbe utile se desideri solo estrarre una particolare parte di dati dal file HTML (o dalla pagina web). Ed è esattamente qui che entra in gioco XPath, un linguaggio di interrogazione per selezionare elementi da un documento XML/HTML.
Metodi Efficaci per l’Estrazione di Testo da HTML
Ci sono due cose che puoi provare per catturare il testo dai file HTML.
Linguaggio di Programmazione
Per quei documenti HTML semplici, quelli che hanno conoscenze di base di programmazione sceglierebbero di scrivere un programma per rimuovere tutti i tag HTML e conservare solo il testo all’interno dei file HTML, utilizzando Espressioni Regolari o XPath. Esistono diversi linguaggi di programmazione ampiamente utilizzati come C#, Java, Python, JS, PHP, Go e NodeJs che sono disponibili per i programmatori.
Alcuni di questi linguaggi hanno il proprio parser per HTML disponibile gratuitamente e potrai conoscere meglio questi parser HTML cliccando qui https://en.wikipedia.org/wiki/Comparison_of_HTML_parsers.
Il testing e il debug del tuo codice possono richiedere del tempo, il che dovrebbe essere ben previsto se hai avuto esperienza con la programmazione.
Strumenti di Estrazione Dati sul Web
Ci sono molti strumenti di estrazione web potenti, come Octoparse, disponibili per raccogliere praticamente tutto sulla pagina web, inclusi testi, link, immagini, ecc. Si può convertire tutto ciò che ottieni in un formato di dati strutturato.
Non c’è bisogno di alcuna programmazione, quindi è adatto a coloro che non hanno esperienza di programmazione. Nella maggior parte dei casi, non è necessario scrivere Espressioni Regolari o XPath, ma sarà sempre un vantaggio se si desidera soddisfare requisiti di dati più sofisticati. Octoparse, essendo progettato per non programmatori, ha un’interfaccia utente amichevole che ti permette di interagire facilmente con le pagine web. È facile gestire ed esportare i dati senza un ambiente di sviluppo integrato.
Se sei un non-programmatore, la modalità di rilevamento automatico di Octoparse sarebbe estremamente utile per iniziare. Il software rileverà automaticamente la pagina web e trasformerà i dati desiderati in un foglio di calcolo per te.
Ecco alcune guide pratiche che potrebbero interessarti:
Come estrarre informazioni su prodotti da eBay
Come estrarre annunci immobiliari da Immobiliare.it
Utilizzo Pratico dello Strumento di Estrazione HTML
Se sei ancora un novizio in un qualsiasi linguaggio di programmazione ma desideri scaricare informazioni dalle pagine web con entusiasmo, uno strumento di scraping web può essere estremamente utile. L’algoritmo di auto-rilevamento di Octoparse rende lo scraping dei dati facile anche per non programmatori. Per la maggior parte delle pagine web là fuori, puoi farlo in soli tre semplici passaggi.
- Inserire l’URL di destinazione
- Avviare il rilevamento automatico
- Eseguire l’attività per lo scraping dei dati
Prendiamo questa pagina web come esempio: https://techcrunch.com/
Supponiamo tu voglia raschiare i blog da Techcrunch (o da qualsiasi altro sito web simile), semplicemente inserisci l’URL in Octoparse e avvia il rilevamento automatico, otterrai uno scraper che ti aiuterà a ottenere i dati strutturati come segue:
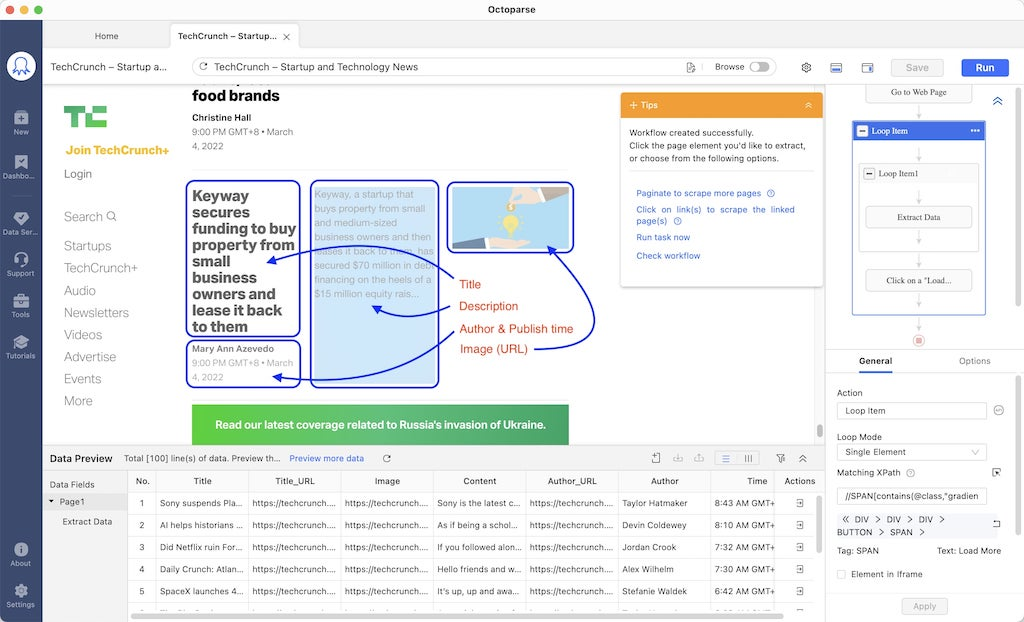
Cliccando sul pulsante “salva”, hai a tua disposizione uno scraper. Puoi eseguire lo scraper ogni volta che hai bisogno dei dati o programmarlo per alimenti regolari.
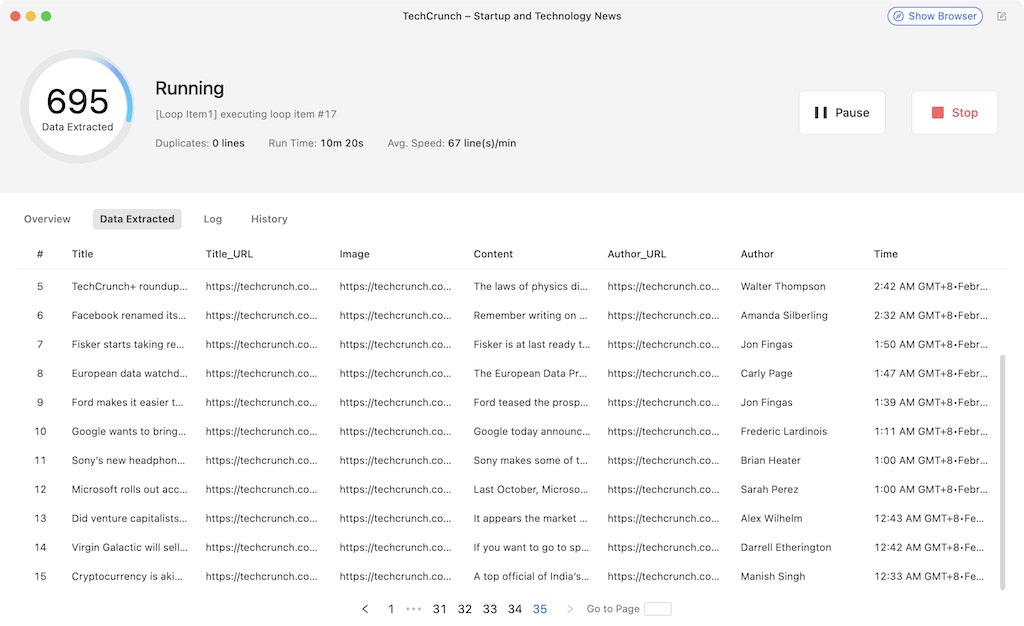
Se opti per le esecuzioni locali, in realtà potrai vedere il processo funzionare in tempo reale. Quando il task è completato, puoi scaricare i dati in Excel, CSV o JSON. Con l’aiuto di Octoparse, l’estrazione dei dati da un file HTML può essere così semplice.




