XPath svolge un ruolo importante quando usi Octoparse per estrarre dati. Riscrivere XPath può aiutarti a gestire pagine mancanti, dati mancanti o duplicati, ecc. Sebbene XPath possa sembrare intimidatorio all’inizio, non deve esserlo. In questo articolo, ti introdurrò brevemente cos’è XPath e come può essere utilizzato per ottenere i dati accurati e precisi.
Cos’è XPath
XPath (XML Path Language) è un linguaggio di query per selezionare elementi da un documento XML/HTML. Può aiutarti a trovare in modo preciso e veloce un elemento nel documento intero.
Le pagine web sono generalmente scritte in un linguaggio chiamato HTML. Se carichi una pagina web su un browser (Chrome, Firefox, ecc.), puoi facilmente accedere al documento HTML corrispondente premendo il tasto F12. Tutto ciò che vedi sulla pagina web può essere trovato all’interno dell’HTML, come un’immagine, blocchi di testo, link, menu, ecc.
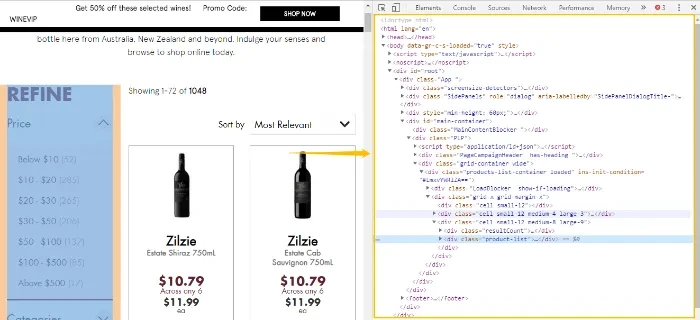
XPath è il linguaggio più comunemente usato quando si ha bisogno di individuare un elemento in un documento HTML. Può essere facilmente inteso come il “percorso” per trovare l’elemento target all’interno del documento HTML. Per spiegare ulteriormente come funziona XPath, diamo un’occhiata a un esempio.

L’immagine mostra una parte di un documento HTML.
L’HTML ha diversi livelli di elementi, proprio come una struttura ad albero. In questo esempio, il livello 1 è “bookstore” e il livello 2 è “book”. “Title”, “author”, “year”, “price” sono tutti elementi del livello 3.
Il testo tra parentesi angolari (<bookstore>) è chiamato un tag. Un elemento HTML solitamente consiste in un tag di apertura e un tag di chiusura, con il contenuto inserito nel mezzo.
<tagname>Il contenuto va qui…</tagname>
XPath usa “/” per collegare i tag di diversi livelli dall’alto verso il basso per specificare la posizione di un elemento. Per il nostro esempio, se vogliamo individuare la posizione dell’elemento “author”, l’XPath sarà:
/bookstore/book/author
Se hai difficoltà a capire come funziona, pensa a come troviamo un partic olare file sul nostro computer.
Per trovare il file chiamato “author”, il percorso esatto del file è \bookstore\book\author. Sembra familiare?
Ogni file sul computer ha il proprio percorso, così come gli elementi di una pagina web. Con XPath, puoi trovare rapidamente e facilmente gli elementi della pagina, proprio come trovare un file sul tuo computer.
L’XPath che parte dall’elemento radice (l’elemento superiore nel documento) e passa attraverso tutti gli elementi intermedi fino all’elemento target è chiamato Xpath assoluto (Absolute XPath).
Esempio: “/html/body/div/div/div/div/div/div/div/div/div/span/span/span…”
Il percorso assoluto può essere lungo e confuso, quindi per semplificare l’Absolute XPath, possiamo usare “//” per fare riferimento all’elemento con cui vogliamo iniziare l’XPath (noto anche come short XPath). Ad esempio, l’XPath breve per /bookstore/book/author può essere scritto come //book/author. Questo XPath breve cercherà l’elemento book indipendentemente dalla sua posizione assoluta nell’HTML, quindi scenderà di un livello per trovare l’elemento target author.
Come utilizzare XPath in Octoparse
Quando hai bisogno di estrarre dati da una pagina web senza dover programmare, solitamente ci sono 3 passaggi:
Passaggio 1: Scarica e registrati gratuitamente al web scraper senza codice Octoparse.
Passaggio 2: Apri la pagina web da cui devi estrarre dati e copia l’URL. Incolla l’URL su Octoparse e avvia l’estrazione automatica. Personalizza il campo dati dalla modalità di anteprima o dal flusso di lavoro sul lato destro.
Passaggio 3: Inizia a estrarre i dati cliccando sul pulsante Esegui. I dati estratti possono essere scaricati come file Excel sul tuo dispositivo locale.
Estrarre pagine web con Octoparse significa in realtà estrarre elementi dai codici HTML. XPath viene utilizzato per individuare gli elementi target nel documento. Prendiamo ad esempio l’azione di paginazione.
Dopo aver selezionato il pulsante successivo per costruire l’azione di paginazione, Octoparse genererà un XPath per individuare il pulsante successivo, in modo da sapere su quale pulsante fare clic.
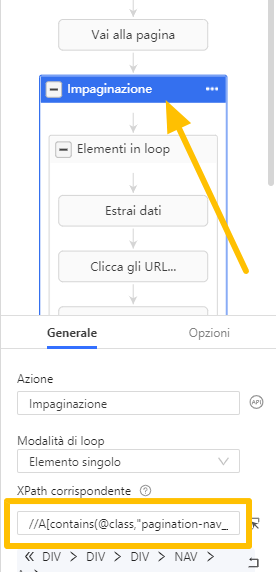
XPath aiuta il crawler a cliccare sul pulsante corretto o ad estrarre i dati target. Qualsiasi azione che desideri che Octoparse esegua è basata sull’XPath sottostante. Octoparse può generare automaticamente gli XPath, ma quelli generati automaticamente non sempre funzionano correttamente. Ecco perché è importante imparare a riscrivere gli XPath.
Quando si affrontano problemi come dati mancanti, loop infiniti, dati non desiderati, dati duplicati, il pulsante successivo che non viene cliccato, ecc., c’è una buona probabilità che questi problemi possano essere risolti facilmente riscrivendo l’XPath.
Come scrivere un XPath (foglio di riferimento incluso)
Prima di iniziare a scrivere un XPath, copriamo prima alcuni termini chiave. Ecco un esempio di HTML che utilizzeremo per la dimostrazione.

Attributo/valore
Un attributo fornisce informazioni aggiuntive su un elemento e viene sempre specificato nel tag iniziale dell’elemento. Un attributo di solito viene in coppie nome/valore come: name=”value”. Alcuni degli attributi più comuni sono href, title, style, src, id, class e molti altri. Puoi trovare il riferimento completo agli attributi HTML.
Nel nostro esempio, id=”book” è l’attributo dell’elemento <div> e class=”book_name” è l’attributo dell’elemento <span>.

Genitore/figlio/fratello
Quando uno o più elementi HTML sono contenuti all’interno di un elemento, l’elemento che contiene gli altri elementi è chiamato genitore (parent), e l’elemento contenuto è un figlio (child) del genitore. Ogni elemento ha un solo genitore, ma può avere zero, uno o più figli. I figli si trovano tra il tag di apertura e il tag di chiusura del genitore.
Nel nostro esempio, l’elemento <body> è il genitore degli elementi <h1> e <div>. Gli elementi <h1> e <div> sono figli dell’elemento <body>.

L’elemento <div> è il genitore dei due elementi <span>. Gli elementi <span> sono i figli dell’elemento <div>.

Gli elementi che hanno lo stesso genitore sono chiamati fratelli (siblings). Gli elementi <h1> e <div> sono fratelli in quanto hanno lo stesso genitore <body>.

I due elementi <span>, entrambi indentati sotto l’elemento <div>, sono anch’essi fratelli.

(Scopri di più tutorial su HTML)
Allora, vediamo insieme più casi d’uso comuni!
Scrivere un XPath per individuare il pulsante Pagina Successiva
Dobbiamo prima ispezionare attentamente il pulsante Pagina Successiva nell’HTML. Nell’HTML di esempio qui sotto, ci sono due cose che spiccano. Innanzitutto, c’è un attributo title con il valore “Next” e, in secondo luogo, il contenuto “Next”.
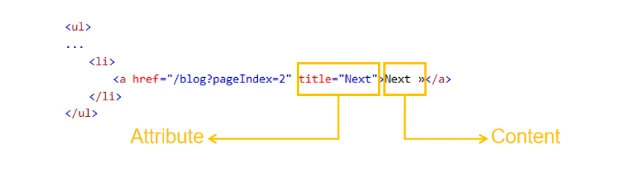
In questo caso, possiamo usare l’attributo title o il testo del contenuto per individuare il pulsante Pagina Successiva nell’HTML.
L’XPath che individua l’elemento <a> che ha un attributo title con il valore “Next” sarebbe scritto così: //a[@title=”Next”]
Questo XPath dice, vai all’elemento <a> il cui attributo title è “Next”. Il simbolo @ viene utilizzato in XPath per indirizzare un attributo.
In alternativa, l’XPath che individua l’elemento <a> che contiene “Next” nel testo del contenuto appare così: //a[contains(text(), “Next”)]
Questo XPath dice, vai all’elemento <a> il cui contenuto contiene il testo “Next”.
Puoi anche utilizzare sia l’attributo title che il testo del contenuto per scrivere l’XPath: //a[@title=”Next” and contains(text(), “Next”)]
Scrivere un XPath per localizzare gli elementi nel loop
Per individuare una lista di elementi su una pagina web, è importante cercare il pattern tra gli elementi della lista. Gli elementi della stessa lista generalmente condividono gli stessi attributi o attributi simili. Nell’esempio HTML qui sotto, vediamo che tutti gli elementi <li> hanno attributi class simili.

Basandoci su questa osservazione, possiamo utilizzare contains(@attributo) per individuare tutti gli elementi della lista.
//li[contains(@class,”product_item”)]
Questo XPath dice: vai all’elemento <li> il cui attributo class contiene “product_item”.
Scrivere un XPath per individuare i campi dati
Individuare un particolare campo dati è molto simile a individuare il pulsante Pagina Successiva utilizzando text() o un attributo.

Supponiamo che vogliamo scrivere un XPath che individua l’indirizzo nell’esempio HTML sopra. Possiamo usare l’attributo itemprop che ha il valore “address” per individuare l’elemento specifico.
//div[@itemprop=”address”]
Questo XPath dice: vai all’elemento <div> che ha l’attributo itemprop con il valore “address”.
Esiste un altro modo per approcciare questo. Nota come l’elemento <div> che contiene l’indirizzo effettivo si trova sempre sotto il suo fratello <div>, uno che ha il contenuto “Location:”. Quindi possiamo prima individuare il testo “Location” e poi selezionare il primo fratello che segue.
//div[contains(text(),”Location”)]/following-sibling::div[1]
Questo XPath dice: vai all’elemento <div> che contiene “Location” nel contenuto, poi vai al primo elemento <div> fratello.
Potresti aver già notato che esistono effettivamente più modi per individuare un elemento nell’HTML. Questo è vero proprio come ci sono sempre più percorsi per qualsiasi destinazione. La chiave è usare il tag, gli attributi, il testo del contenuto, i fratelli, il genitore, o qualsiasi cosa ti aiuti a individuare l’elemento target nell’HTML.
Per semplificarti le cose, ecco un foglio di riferimento con espressioni XPath utili per aiutarti a individuare rapidamente qualsiasi elemento nell’HTML.
| Espressioni | Esempio | Significato |
| * Individua gli sottoelementi | //div/* | Seleziona tutti gli elementi figli dell’elemento <div> element |
| @ Seleziona gli attributi | //div[@id=”book”] | Seleziona tutti gli elementi <div> che hanno un attributo “id” con un valore di “book” |
| text() Trova elementi con testo specifico | //span[text()=”Harry Potter”] | Seleziona tutti gli elementi <span> il cui contenuto è esattamente “Harry Potter” |
| contains() Seleziona gli elementi che contengono una certa string | //span[contains(@class, “price”)] | Seleziona tutti gli elementi <span> il cui valore dell’attributo di classe contiene “price” |
| //span[text(),”Learning”] | Seleziona tutti gli elementi <span> il cui contenuto contiene “Learning” | |
| position() Seleziona gli elementi in una determinata posizione | //div/span[position()=2]//div/span[2] | Seleziona il secondo elemento <span> che è figlio dell’elemento |
| //div/span[position()<3] | Seleziona i primi 2 elementi <span> che sono figli dell’elemento <div> | |
| last() Seleziona l’ultimo elemento | //div/span[last()] | Seleziona l’ultimo elemento <span> che è figlio dell’elemento <div> |
| //div/span[last()-1] | Seleziona l’ultimo penultimo elemento <span> che è figlio dell’elemento <div> | |
| //div/span[position()>last()-3] | Seleziona gli ultimi 3 elementi <span> che sono figli dell’elemento <div> | |
| not Seleziona gli elementi che sono opposti alle condizioni specificate | //span[not(contains(@class,”price”))] | Seleziona tutti gli elementi <span> il cui valore dell’attributo class non contiene “price” |
| //span[not(contains(text(),”Learning”))] | Seleziona tutti gli elementi <span> il cui testo non contiene “Learning”. | |
| and Seleziona gli elementi che corrispondono a più condizioni | //span[@class=”book_name” and text()=”Harry Potter”] | Seleziona tutti gli elementi <span> il cui valore dell’attributo di classe è “book_name” e il cui testo è “Harry Potter” |
| or Seleziona gli elementi che corrispondono a una delle condizioni | //span[@class=”book_name” or text()=”Harry Potter”] | Seleziona tutti gli elementi <span> il cui valore dell’attributo di classe è “book_name” o il cui testo è “Harry Potter” |
| following-sibling Seleziona tutti gli elementi successivi all’elemento corrente | //span[text()=”Harry Potter”]/following-sibling::span[1] | Seleziona il primo elemento <span> dopo l’elemento <span> il cui testo è “Harry Potter” |
| preceding-sibling Seleziona tutti i fratelli prima dell’elemento corrente | //span[@class=”regular_price”]/preceding-sibling::span[1] | Seleziona il primo elemento <span> prima dell’elemento <span> il cui valore dell’attributo di classe è “regular_price” |
| .. Seleziona il genitore dell’elemento corrente | //div[@id=”bookstore”]/.. | Seleziona il genitore dell’elemento <div> il cui valore dell’attributo id è “bookstore” |
| | Seleziona più percorsi | //div[@id=”bookstore”] | //span[@class=”regular_price”] | Seleziona tutti gli elementi <div> il cui valore dell’attributo id è “bookstore” e tutti gli elementi <span> il cui valore dell’attributo class è “regular_price”. |
XPath di corrispondenza e XPath relativo (per il loop)
Finora abbiamo trattato come scrivere un XPath quando è necessario estrarre un elemento direttamente da una pagina web. Tuttavia, ci sono momenti in cui potresti dover prima costruire una lista di elementi target e poi estrarre i dati da ciascun elemento. Ad esempio, quando devi estrarre dati da pagine di risultati come questa (https://www.paginegialle.it/ricerca/bar/Roma).
In questo caso, non solo è necessario conoscere XPath corrispondente (che useresti per catturare un elemento direttamente), ma anche XPath relativo, quello che specifica la posizione dell’elemento specifico della lista rispetto alla lista.
In Octoparse, quando modifichi l’XPath di un campo dati, vedrai che ci sono due caselle XPath.
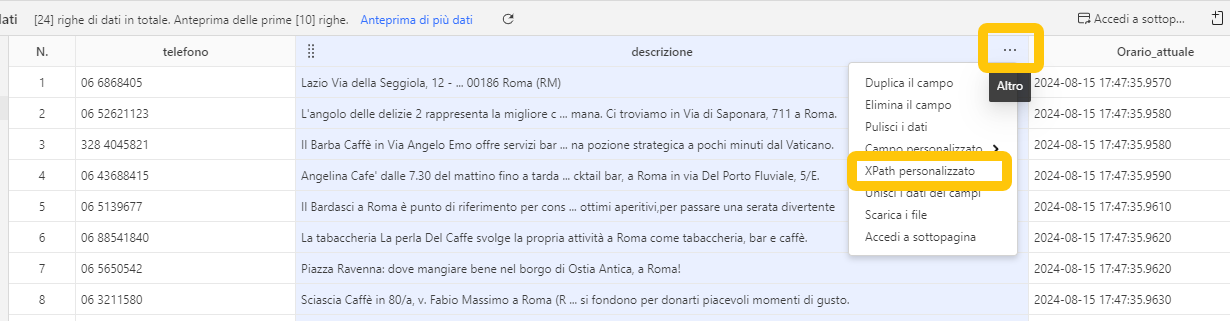
XPath corrispondente viene utilizzato quando estraiamo dati direttamente dalla pagina web.
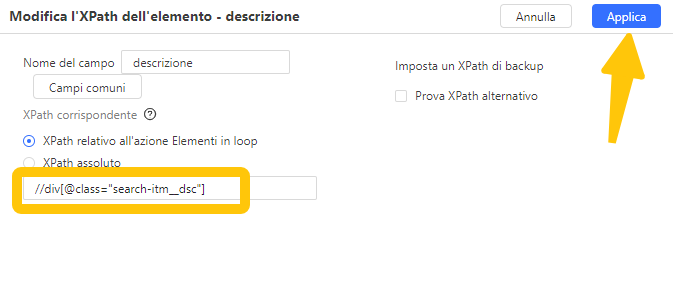
XPath relativo viene utilizzato quando estraiamo dati da un elemento in un loop. L’XPath relativo in Octoparse è una parte aggiuntiva dell’XPath corrispondente rispetto all’XPath degli elementi in loop.

Ad esempio, se vogliamo creare una lista a loop di elementi <li> e raschiare un elemento contenuto all’interno dei singoli elementi <li> nella lista, possiamo utilizzare l’XPath //ul[@class=”results”]/li per individuare l’a lista’elenco.
Supponiamo che l’XPath di corrispondenza di un elemento nella lista sia //ul[@class=”results”]/li/div/a[@class=”link”].
In questo caso, l’XPath relativo dovrebbe essere /div/a[@class=”link”]. Oppure possiamo semplificare questo XPath relativo usando “//” in //a[@class=”link”]. È sempre consigliato usare “//” quando si scrive uno XPath relativo poiché rende l’espressione più concisa.
Ora potresti aver già notato che quando l’XPath per la lista a loop e l’XPath relativo vengono combinati in uno XPath, si ottiene esattamente l’XPath di corrispondenza per l’elemento del loop.
4 semplici passaggi per correggere il tuo XPath
Passaggio 1: Apri la pagina web utilizzando un browser con uno strumento XPath (uno che ti permetta di visualizzare l’HTML e cercare una query XPath). XPath Helper (un’estensione per Chrome) è sempre consigliato se usi Chrome.
Passaggio 2: Una volta che la pagina web è caricata, ispeziona l’elemento target nell’HTML.
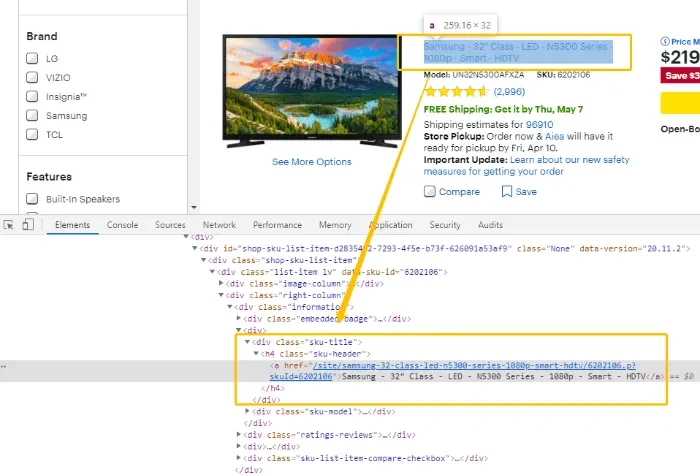
Passaggio 3: Ispeziona attentamente l’elemento HTML, così come gli elementi vicini. Vedi qualcosa che si distingue e che potrebbe aiutarti a identificare e individuare l’elemento target? Forse un attributo di classe come class=”sku-title” o class=”sku-header”?

Usa il foglio di riferimento sopra per scrivere uno XPath che selezioni l’elemento esclusivamente e precisamente. Il tuo XPath dovrebbe corrispondere solo all’elemento(i) target e a nient’altro nell’intero documento HTML. Utilizzando XPath Helper, puoi sempre testare per vedere se l’XPath riscritto funziona correttamente.
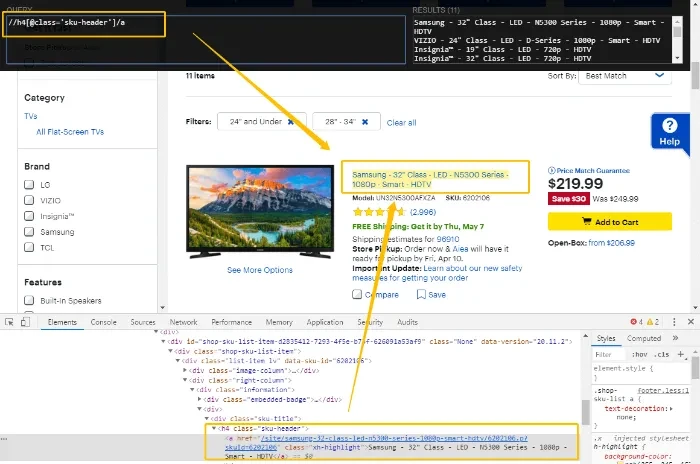
Passaggio 4: Sostituisci l’XPath generato automaticamente in Octoparse.
Tutorial sulla risoluzione dei problemi con XPath
Nella maggior parte dei casi, non è necessario scrivere l’XPath da soli. Ma ci sono alcune situazioni in cui potresti dover fare alcune modifiche per raschiare in modo più preciso.
Problemi con i loop
Elementi mancanti nel loop: è impostato lo scorrimento infinito ma non vengono aggiunti nuovi elementi al dataset?
Problemi con i campi dati
Raschiare un campo sbagliato: perché i dati non sono stati estrapolati nei campi dati giusti?
Strumenti per XPath
Non è facile controllare il codice HTML direttamente in Octoparse, quindi dobbiamo usare altri strumenti per aiutarci a generare uno XPath.
Chrome/qualsiasi browser
Puoi ottenere uno XPath per un elemento facilmente con qualsiasi browser. Prendiamo Chrome come esempio.
- Apri la pagina web in Chrome
- Fai clic con il tasto destro sull’elemento di cui vuoi trovare l’XPath
- Scegli “Ispeziona” e vedrai gli Strumenti di sviluppo di Chrome (Chrome DevTools)
- Fai clic con il tasto destro sull’area evidenziata nella console.
- Vai a Copia -> Copia XPath
Ma l’XPath copiato a volte è uno XPath assoluto quando non ci sono attributi o il valore dell’attributo è troppo lungo. Potresti comunque dover scrivere l’XPath corretto.
XPath Helper
XPath Helper è una fantastica estensione per Chrome che ti consente di cercare XPath semplicemente passando sopra l’elemento dal browser. Puoi anche modificare direttamente la query XPath nella console. Otterrai immediatamente il risultato (o i risultati) così saprai se il tuo XPath funziona correttamente o no.
Più tutorial su XPath:



