I CAPTCHA sono una delle tecniche anti-scraping più diffuse implementate dai proprietari di siti web. reCAPTCHA v3 è una soluzione CAPTCHA di Google progettata per rilevare il traffico generato da bot sui siti. NuCaptcha è una soluzione CAPTCHA avanzata. Tuttavia, i CAPTCHA risultano spesso irritanti, non solo per gli utenti, ma anche per i software di web scraping. Risolvere i CAPTCHA rappresenta una delle principali sfide affrontate dai web scraper. Leggi questo approfondimento per scoprire diversi modi per superare i CAPTCHA mentre estrai contenuti dal sito di tuo interesse. Ecco come è strutturato l’articolo:
Cos’è un CAPTCHA? E Che Cosa è un reCAPTCHA?
Il Completely Automated Public Turing Test to Tell Computers and Humans Apart (CAPTCHA) è un test automatizzato, generato tramite algoritmi, che può essere di tipo testuale, visivo o audio. Risolvere i CAPTCHA richiede tre abilità in cui gli esseri umani superano nettamente i computer:
- Riconoscimento invariante (identificazione di forme diverse, immagini dello stesso alfabeto e oggetti);
- Segmentazione (riconoscimento di alfabeti sovrapposti);
- Analisi contestuale (comprensione olistica dell’immagine, del testo o dell’audio).
reCaptcha è la soluzione per CAPTCHA più popolare, sviluppata da Google. È facilmente integrabile in un sito web per aumentare la sicurezza contro i bot.
Quali Sono i Tipi Comuni di CAPTCHA
1. CAPTCHA normale
È il tipo di CAPTCHA più utilizzato, in cui un’immagine distorta contiene del testo che, sebbene alterato, rimane leggibile per gli esseri umani. Per risolvere un CAPTCHA normale, è necessario inserire il testo distorto nella casella di testo fornita.
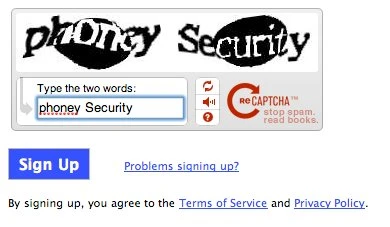
2. CAPTCHA basato su testo
TextCaptcha non è molto popolare, ma è eccellente per gli utenti ipovedenti. Non è basato su immagini, bensì esclusivamente su testo. Un esempio di richiesta CURL per TextCaptcha:
$ curl http://api.textcaptcha.com/[email protected]
{ “q”: “Se domani è sabato, che giorno è oggi?”,
“a”: [ “f6f7fec07f372b7bd5eb196bbca0f3f4”,
“dfc47c8ef18b4689b982979d05cf4cc6” ]}
CAPTCHA: Se domani è sabato, che giorno è oggi?
SOLUZIONE: Venerdì.
3. Key Captcha
KeyCaptcha è un altro servizio di integrazione CAPTCHA in cui dovresti risolvere un puzzle.

4. CAPTCHA basato su immagini
I CAPTCHA basati su immagini che rientrano nella categoria dei puzzle di classificazione sono i Click CAPTCHA. reCaptcha, ASIRRA e il Ghost Captcha di Snapchat sono esempi popolari di Click CAPTCHA basati sulla classificazione.

5. Rotate Captcha
Questi sono puzzle CAPTCHA basati sull’orientamento delle immagini. Nei Rotate CAPTCHA, è necessario fare clic una o più volte per ruotare un’immagine affinché soddisfi i criteri di verifica. La condizione di verifica più comune è posizionare un oggetto nella “giusta posizione verticale”. FunCaptcha è uno dei fornitori di integrazione per i Rotate CAPTCHA, ma sembra avere problemi di funzionamento. RVerify.js è una libreria open-source in JavaScript per verificare l’orientamento delle immagini.
6. GeeTest CAPTCHA
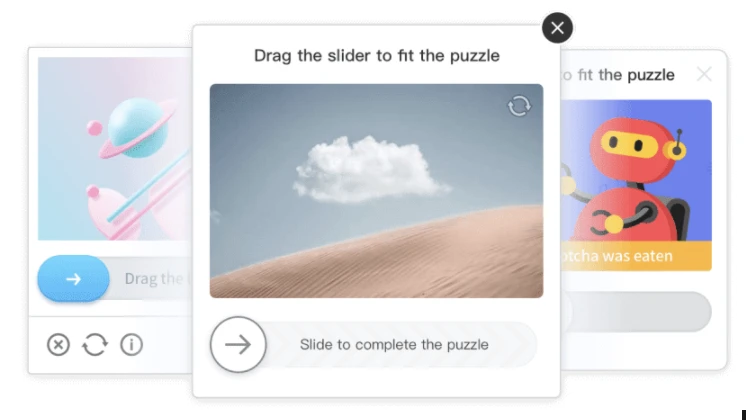
I GeeTest CAPTCHA sono interessanti, in quanto è necessario spostare un pezzo del puzzle, spesso trascinando un cursore, oppure selezionare determinate immagini in un ordine specifico.
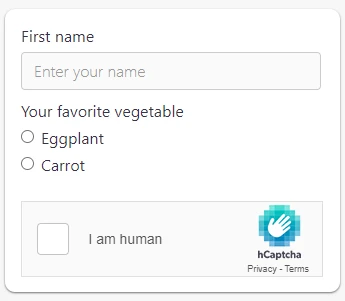
7. hCaptcha
hCaptcha è molto simile a reCaptcha. L’unica differenza è che quando utilizziamo hCaptcha, diverse aziende possono beneficiare del data labeling che gli utenti forniscono sui siti web quando cliccano su di essi. Con reCaptcha, solo Google beneficia del data labeling crowdsourced.
8. Capy Puzzle
Simile a keyCaptcha, Capy Puzzle è un servizio CAPTCHA basato su puzzle. CAPY.ME è un servizio che consente di integrare i puzzle Capy nei siti web.

Scopri di più su i diversi tipi di CAPTCHA.
Perché i Siti Web Applicano CAPTCHA
Oggi, l’informatica è diventata pervasiva e i compiti e servizi computerizzati sono comuni, quindi i livelli di sicurezza aumentati sono diventati più importanti. Lo sviluppo di CAPTCHA per i computer serve a garantire che stiano affrontando esseri umani in situazioni in cui l’interazione umana è essenziale per la sicurezza, ad esempio, accedere a un sito web o effettuare pagamenti su Internet.
Il CAPTCHA blocca anche gli spammer e i bot che cercano di raccogliere automaticamente dati online, iscriversi automaticamente a siti web, blog o forum. Protegge i siti web dall’essere invasi da spam, registrazioni fraudolente e altri comportamenti illegali.
Come Risolvere i CAPTCHA nel Processo di Web Scraping
Sia che tu stia eseguendo lo scraping utilizzando uno strumento avanzato di “click and scrape” senza codice, o che il tuo scraper sia scritto in Python, Java o Javascript, è possibile risolvere e aggirare tutti i tipi di CAPTCHA. Anche se nessun servizio/soluzione garantisce una percentuale di successo del 100% nel risolvere i CAPTCHA, è possibile raggiungere un’efficienza fino al 90% utilizzando strumenti popolari come DeathByCaptcha e 2captcha, ecc.
Ci sono due approcci più usati per risolvere i CAPTCHA.
Risoluzione CAPTCHA basata su operazioni umane
I CAPTCHA sono progettati per essere risolti dagli esseri umani. Esistono aziende che impiegano migliaia di persone per risolvere questi CAPTCHA in tempo reale, a un prezzo molto basso. L’efficienza è piuttosto alta, ma la latenza temporale è un problema con questo approccio.
Come dovresti utilizzare un servizio di risoluzione CAPTCHA durante lo scraping?
Esistono diversi fornitori di servizi di risoluzione CAPTCHA nel mercato, alcuni dei più noti sono:
- DeathByCaptcha
- AZCaptcha
- ImageTyperZ
- EndCaptcha
- BypassCaptcha
- CaptchaTronix
- AntiCaptcha
- 2Captcha
- CaptchaSniper
Tutti questi fornitori di servizi adottano un approccio simile:
- Registrati sul loro sito web, ottieni un token e le credenziali dopo aver pagato l’importo, o forse gratuitamente se c’è una prova disponibile.
- Implementa la loro API/plugin utilizzando un linguaggio di tua scelta, ad esempio Python, PHP, Java, JS, ecc.
- Invia i tuoi CAPTCHA alle loro API.
- Ricevi i CAPTCHA risolti nella risposta dell’API.
Risoluzione dei CAPTCHA tramite OCR (Riconoscimento Ottico dei Caratteri)
Questo è un approccio programmatico per risolvere i CAPTCHA. OCR sta per riconoscimento ottico dei caratteri o lettore ottico dei caratteri. L’OCR è un metodo elettronico o meccanico per convertire il testo digitato, scritto a mano o stampato in testo codificato dalla macchina. Puoi fornire a un OCR un documento scansionato, una foto o una scena (ad esempio, cartelloni pubblicitari). Esistono strumenti open-source come TESSERACT, GOCR, OCRAD, ecc., che ti permettono di iniziare senza dover partire da zero. Gli OCR hanno la capacità di risolvere con successo diversi tipi di CAPTCHA basati su immagini.
Auto-risoluzione
Se stai eseguendo uno scraping su un singolo sito che verifica i veri utenti utilizzando reCAPTCHA solo occasionalmente, potresti voler bypassare il reCaptcha manualmente da solo. In questi casi, puoi configurare il tuo flusso di lavoro di scraping per:
- rilevare un reCAPTCHA, e mentre lo risolvi
- mettere in pausa lo scraping per un tempo specificato, ad esempio 7-8 secondi, oppure
- attendere che un elemento sulla pagina diventi visibile, oppure
- attendere il tuo input fino a quando non inizia nuovamente lo scraping.
- Una volta risolto il CAPTCHA, puoi riprendere lo scraping come di consueto.
Per rilevare un reCAPTCHA, è importante capire come viene implementato.
Come viene integrato reCaptcha nei siti web?
L’integrazione di reCaptcha prevede i seguenti passaggi:
1. Caricamento dell’API Javascript
2. Chiamare una funzione per gestire il callback e legarla a un pulsante o a un’azione.
Funzione:
Ora, se desideri rilevare un captcha, utilizza gli XPaths e rileva un reCaptcha cercando un elemento con una classe che contenga “recaptcha”.
Xpath: //*[contains(@class, “recaptcha”)]
Se un elemento è presente, significa che c’è un CAPTCHA sulla pagina che deve essere risolto. Puoi mettere in pausa il tuo scraper, risolvere il CAPTCHA e riprendere lo scraping una volta che è stato risolto.
Come Bypassare reCaptcha in Octoparse
Cos’è Octoparse?
Come accennato in precedenza, è possibile eseguire scraping sul web utilizzando soluzioni no-code come Click & Scrape. Octoparse è una delle soluzioni di web scraping no-code più avanzate nel mercato. È possibile scaricarlo gratuitamente per iniziare a fare scraping sul web, e offre anche piani molto convenienti per scraping scalabile e veloce. Se sei nuovo su Octoparse, puoi trovare risorse utili per imparare ad usarlo. Se invece sei già familiare con Octoparse, ecco come puoi risolvere i CAPTCHA su Octoparse:
Scraping su dispositivo locale
Quando utilizzi Octoparse per eseguire scraping sul tuo computer locale, è consigliato utilizzare le funzionalità di “attendere prima dell’esecuzione” o “attendere fino a quando un elemento specifico appare” che sono offerte sotto le opzioni di personalizzazione avanzata del flusso di lavoro di Octoparse. Queste opzioni possono aiutarti a gestire eventuali CAPTCHA che potrebbero comparire durante il processo di scraping. A causa di aggiornamenti della versione, se non vedi l’opzione, consulta il centro assistenza per il supporto!
Scraping su cloud
Per progetti più grandi, il team di Octoparse offre un servizio di personalizzazione dei modelli JavaScript per aggirare i problemi relativi ai CAPTCHA/reCAPTCHA. Questo servizio avanzato è particolarmente utile quando si affrontano pagine web che integrano misure anti-bot robuste come il reCAPTCHA, poiché consente di implementare soluzioni più mirate ed efficaci per superare questi ostacoli.
Suggerimenti per prevenire che i CAPTCHA interrompano la tua esperienza di scraping
1. Usa proxy IP rotanti, cambia frequentemente gli user agent e cancella i cookie
Normalmente, i siti web attivano un servizio integrato di rilevamento anti-scraping quando lo stesso IP inizia a fare troppe richieste ai server. Se utilizzi migliaia di proxy e li ruoti, potresti evitare che i CAPTCHAs vengano attivati.
2. Rispettare il file Robots.txt
Il file robots.txt contiene le regole preferenziali del sito web. Ad esempio, stabilisce se il sito ti consente di fare scraping o no, e se sì, quali URL non vuoi che vengano scrappati, eccetera.
3. Usa browser headless
Se stai scrivendo il tuo scraper, utilizza un browser headless. Strumenti come Octoparse si occupano automaticamente di questo, poiché sono browser intelligenti senza interfaccia grafica.
4. Usa gli header e i referrers nelle tue richieste al server
Se non stai utilizzando un browser completo, è utile includere gli header e i referrers nelle tue richieste al server.
5. Salva i cookie per fare scraping su dati dietro login
Se stai facendo scraping su dati protetti da login, salva i cookie per evitare di dover fare login ogni volta. In Octoparse, questo è facilmente realizzabile.
6. Attenzione alle trappole honeypot invisibili
I siti web possono avere elementi o link invisibili (honeypots). Se il tuo crawler clicca su questi link, il sito capirà che stai usando un bot, poiché un umano non può cliccare su questi link usando un browser come Chrome o Firefox.
7. Mantieni ritardi casuali tra le richieste successive
Per evitare di attivare CAPTCHAs, è consigliabile mantenere ritardi casuali tra le richieste successive, soprattutto quando colpisci lo stesso sito web con gli stessi indirizzi IP in modo ripetitivo.
8. Usa servizi di risoluzione CAPTCHA
Conclusione
Lo scraping del web per estrarre dati è fondamentale per le aziende che desiderano acquisire insight e prendere decisioni aziendali strategiche basate sui dati. I dati web sono anche cruciali per l’addestramento degli algoritmi di machine learning. In questo articolo, abbiamo esplorato i diversi tipi di CAPTCHA, esaminato diversi approcci per risolvere reCaptcha e prevenire i CAPTCHA, e parlato di come risolverli utilizzando Octoparse. Per progetti di grandi dimensioni, offriamo anche un servizio di personalizzazione dei template JavaScript per integrare i principali servizi di risoluzione CAPTCHA in Octoparse.



