Indubbiamente, stiamo vivendo in un’epoca caraterizzata dall’esplosione delle informazioni. Si stima che entro il 2024 verranno generati quotidianamente circa 402,74 milioni di terabyte di dati, che corrispondono a circa 147 zettabyte di dati all’anno. Gli utenti generano innumerevoli testi ogni secondo su Internet. Prendendo come esempio Twitter, ora X, vengono pubblicati 6.000 tweet ogni secondo, con un risultato di oltre 350.000 tweet al minuto, 500 milioni di tweet al giorno e circa 200 miliardi di tweet all’anno. La sfida consiste nell’estrarre solo le informazioni rilevanti da questa inondazione di dati. Ed è qui che entra in gioco il text mining.
Cos’è il Text Mining
Il text mining, noto anche come estrazione del testo, è una tecnica che consente di estrarre informazioni di alta qualità da un numero infinito di testi. Si basa sull’elaborazione del linguaggio naturale (NLP) ed è combinato con alcuni degli algoritmi di data mining tipici, come la classificazione, il clustering, le reti neurali, ecc. Inoltre, il text mining è ampiamente utilizzato per l’analisi sentimentale, l’estrazione di informazioni, la modellazione degli argomenti, ecc.
Nel frattempo, il text mining è strettamente legato ai modelli di linguaggio di grandi dimensioni (LLM) e all’intelligenza artificiale (AI). Il text mining estrae dati rilevanti e di alta qualità da ampi corpus per ottenere approfondimenti più ricchi. Come strumento, il text mining può aiutare gli LLM e i sistemi di AI a migliorare il loro addestramento, le prestazioni e a consentire interazioni personalizzate e consapevoli del contesto.
Compiti principali nel Text Mining
La categorizzazione del testo, il clustering del testo, la produzione di tassonomie granulari, il riassunto dei documenti, ecc., sono progetti tipici di text mining. Qui ti presenteremo alcuni dei compiti più comuni nel text mining.
Classificazione del Testo
L’obiettivo della classificazione del testo o text categorization è suddividere il testo in classi o etichette specifiche in base al suo contenuto. In questo modo, è possibile organizzare, ordinare e gestire grandi volumi di dati testuali. Ad esempio, puoi utilizzarlo per rilevare lo spam nelle email, evitando così di dover gestire messaggi inutili. La classificazione del testo è utilizzata in varie applicazioni, come il rilevamento di email spam, la classificazione degli argomenti negli articoli di notizie e la classificazione delle intenzioni nelle interazioni di servizio clienti.
Estrazione delle Entità
L’estrazione delle entità comporta l’identificazione e la classificazione delle entità nel testo in categorie predefinite, come i nomi di persone, organizzazioni, luoghi, date, ecc. Questo processo aiuta a convertire il testo non strutturato in dati strutturati, migliora i risultati di ricerca identificando e mettendo in evidenza le entità chiave nei documenti e fornisce preziosi spunti dai dati testuali.
Nuvola di Etichette
Una nuvola di etichette, nota anche word cloud o tag cloud in inglese, è una rappresentazione visiva dei dati testuali, dove la dimensione di ciascuna parola indica la sua frequenza o importanza in un testo o dataset dato. Molte aziende applicano visualizzazioni dei dati come questa per analizzare recensioni, post sui social media e articoli al fine di valutare il feedback dei clienti e le menzioni del marchio. In questo modo, possono misurare più accuratamente il sentiment del mercato e le aree su cui concentrarsi.
Analisi del Sentiment
L’analisi del sentimento è un processo che può aiutarti a identificare il sentimento delle opinioni basato sulle parole. È un campo del processamento del linguaggio naturale (NLP) che riguarda la determinazione del tono emotivo o del sentimento espresso in un testo. Le applicazioni più comuni sono l’analisi delle recensioni dei clienti, il monitoraggio del sentiment pubblico verso i marchi sui social media e la conduzione di ricerche di mercato.
Topic Modeling
La modellazione degli argomenti può aiutare a identificare l’argomento di un testo. L’Allocazione Latente di Dirichlet (LDA) è un esempio di modellazione degli argomenti che potrebbe classificare il testo in un documento a un particolare argomento. Costruisce un modello di argomento per documento e un modello di parole per argomento, modellato come distribuzioni di Dirichlet, come il tagging per recensioni/articoli/notizie.
Cosa può fare il Text Mining in diverse industrie
Il text mining può fornire preziose informazioni e vantaggi in vari settori.
E-commerce
Nel settore dell’e-commerce, il text mining può essere applicato per migliorare l’esperienza del cliente, ottimizzare le operazioni e prendere decisioni strategiche. Inoltre, il text mining è uno strumento eccellente per alimentare chatbot e assistenti virtuali in grado di rispondere automaticamente alle richieste dei clienti. Di conseguenza, puoi migliorare il supporto e il servizio clienti per offrire un’esperienza migliore ai tuoi utenti.
Sanità
Nel settore sanitario, ci sono molti materiali per il text mining. Prendendo come esempio le cartelle cliniche, puoi estrarre informazioni cruciali dai registri dei pazienti, come sintomi, diagnosi e piani di trattamento, per supportare le decisioni e migliorare la cura del paziente. Inoltre, analizzare prove cliniche e articoli scientifici può aiutare a identificare nuovi candidati per farmaci e potenziali effetti collaterali dei trattamenti.
Educazione
Lo sviluppo del curriculum e il supporto agli studenti possono trarre vantaggio dal text mining. Puoi sviluppare intuizioni da risorse educative e ricerche per informare la progettazione del curriculum. Inoltre, monitorando e analizzando le richieste e le interazioni degli studenti, puoi capire come fornire supporto mirato e migliorare l’esperienza di apprendimento.
Settore pubblico e governativo
Per i dipartimenti governativi, il text mining è stato utilizzato per analizzare i commenti pubblici, i documenti politici e i testi legislativi al fine di informare lo sviluppo delle politiche e la presa di decisioni per molti anni. Con lo sviluppo rapido di Internet, molte persone applicano il text mining per monitorare e analizzare l’opinione pubblica su vari temi attraverso i social media, le notizie e le comunicazioni, al fine di guidare le azioni e le risposte del governo.
Oltre ai settori sopra menzionati, il text mining è apprezzato in sempre più ambiti. Nel settore finanziario, svolge un ruolo nell’identificazione di potenziali frodi, mentre chi lavora nelle aziende legali lo utilizza per trovare informazioni chiave e clausole rilevanti. Qualunque sia l’industria in cui ti trovi, il text mining è uno strumento efficace in ogni caso.
Octoparse – Il Miglior Strumento per il Text Mining
Prima di iniziare un progetto di text mining, è necessario ottenere i dati grezzi da qualche fonte. L’acquisizione dei dati è il primo e più importante passo prima di procedere con il text mining. Potresti trovare dati open-source su piattaforme come Kaggle. Tuttavia, i dataset su tali piattaforme sono stati utilizzati così tanto che è difficile condurre un progetto unico basato su queste fonti. Per risolvere questo problema, è più ragionevole costruire uno scraper per estrarre dati freschi e aggiornati da Internet.
Octoparse è uno strumento di web scraping senza codice, utilizzabile da chiunque, indipendentemente dalle competenze di programmazione. È in grado di estrarre vari attributi degli elementi web, come testi e URL. Durante il processo di scraping con Octoparse, fai clic sui dati di destinazione e seleziona “Testo” dal pannello dei suggerimenti. Dopo di che, raccoglierai i dati di testo desiderati dai siti web. In alternativa, puoi utilizzare la funzione di rilevamento automatico per consentire a Octoparse di scansionare l’intera pagina e rilevare i dati di testo estraibili per te. Successivamente, puoi visualizzare direttamente i campi di dati rilevati e ottenere i dati necessari. Di conseguenza, avrai a disposizione una fonte di testi sufficiente per il text mining.
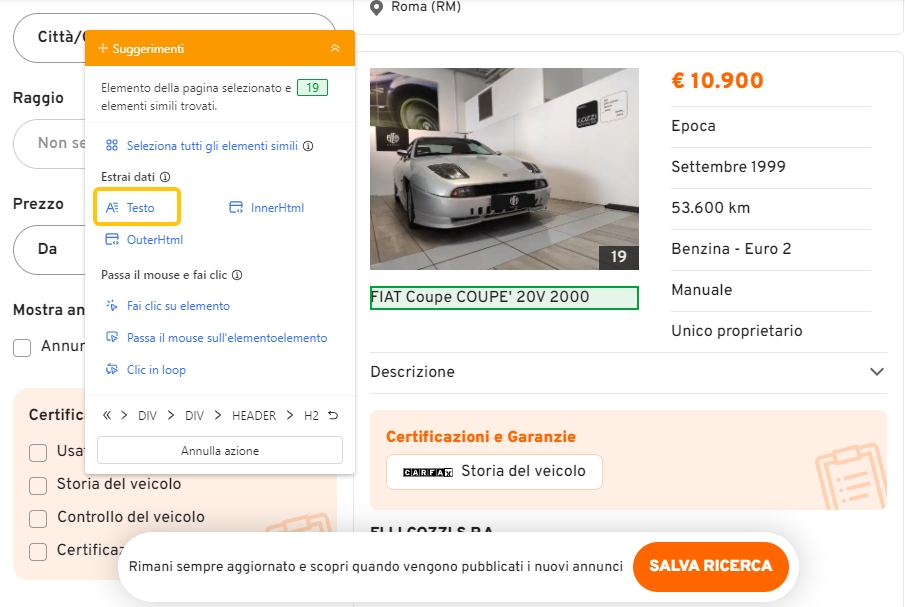
Vuoi saperne di più su come estrarre dati da URL o HTML? Controlla QUI.
Conclusione
Il text mining trasforma i testi grezzi in dati strutturati, consentendo analisi più approfondite e aiutando le organizzazioni a prendere decisioni informate. Il web scraping è una parte fondamentale del text mining, poiché è il modo più efficace per raccogliere dati di testo in grandi quantità da utilizzare per il mining. Prova Octoparse ora e immergiti nel text mining!



