Man mano che le filosofie dell’intelligenza artificiale e dei big data si diffondono, potrebbe essere necessario estrarre dati da molti link. Estrarre tutti gli indirizzi dei collegamenti ipertestuali presenti su una pagina web è il primo e più importante passaggio in questo contesto. Questo consente di esplorare ogni URL per raccogliere vari elementi web, come immagini, testo o link all’interno del collegamento ipertestuale, per un’analisi più approfondita.
Un estrattore di collegamenti più intelligente può rendere il processo di estrazione più efficiente e contribuire all’analisi SEO, all’analisi dei competitor, alla creazione di contenuti e altro ancora. In questo post vi presenteremo i 10 migliori strumenti di web scraping per l’estrazione di link.
I 10 Migliori Strumenti per Scaricare URL
1. Octoparse
Octoparse è un potente ma gratuito strumento di web scraping che consente di estrarre HTML interno/esterno e link da diverse aree dei tag. È una soluzione senza codice, adatta a chiunque desideri estrarre dati senza scrivere una sola riga di codice.
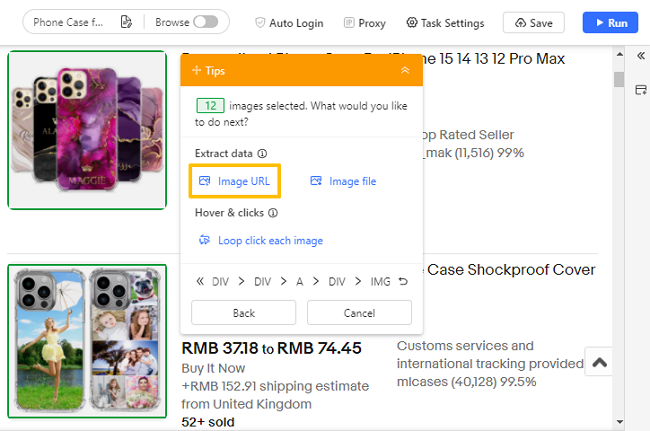
I hyperlink sono URL cliccabili che aprono nuove pagine o ti indirizzano a nuovi siti web. Quando ottieni gli URL, puoi accedere e scaricare i file o le immagini corrispondenti tramite questi link. Mentre esegui lo scraping dei link utilizzando Octoparse, devi solo cliccare sui dati di destinazione e selezionare Link dal pannello dei suggerimenti. Inoltre, cliccando sulle immagini della pagina e selezionando URL immagine dal pannello dei suggerimenti, puoi ottenere i loro collegamenti. Oltre a estrarre link, Octoparse può raccogliere vari elementi dai siti web. Che tu abbia bisogno di testo o HTML, puoi configurare un estrattore in pochi semplici passaggi utilizzando Octoparse.
2. Apify
Apify è una piattaforma per il web scraping. Gli utenti possono trovare strumenti pronti all’uso e modelli di codice per estrarre dati dai siti web. Molti estrattori di link sono progettati e caricati da sviluppatori disponibili su Apify, e la maggior parte di essi è facile da usare e consente di gestire attività di web scraping senza una vasta conoscenza della programmazione. Tuttavia, se non hai alcuna esperienza in codifica, la curva di apprendimento potrebbe essere ripida.
3. Bright Data
Bright Data è un’azienda che offre servizi di raccolta dati web per aziende B2B. Fornisce agli utenti vari strumenti e API per il web scraping per diversi scopi. L’estrattore di URL su Bright Data è preimpostato, e puoi utilizzarlo per raccogliere URL da siti di e-commerce, social media, siti immobiliari e altro ancora. Ma ti preghiamo di prestare attenzione ai costi. Utilizzare i servizi di Bright Data potrebbe essere costoso se hai bisogno di scraping ad alto volume o intensivo.
4. WebHarvy
WebHarvy è un software di web scraping point-and-click che consente agli utenti di estrarre facilmente dati web, inclusi URL. Quando estrai URL utilizzando WebHarvy, puoi usare la sua Espressione Regolare preimpostata per ottenere link dall’HTML anziché scriverne una tu stesso.
5. Link Grabber
Link Grabber è un estrattore, specialmente per i hyperlink su pagine HTML. Essendo un’estensione di Chrome, è leggero e facile da usare. Può anche filtrare i link in base a corrispondenze di sottostringhe e raggruppare i link per dominio, risparmiando tempo nella pulizia dei dati estratti. Tuttavia, può estrarre solo link da siti web; se hai bisogno di ulteriori dati come testo e immagini, probabilmente non è la scelta migliore.
6. Link Gopher
Questo è un altro strumento leggero con un focus sull’estrazione di link. Può estrarre tutti i link da una pagina web, inclusi i link incorporati, ordinarli, rimuovere i duplicati e mostrarli in una nuova scheda per il copia e incolla. Utilizzare questo strumento per estrarre link richiede solo un clic per scegliere l’opzione Estrai, e poi puoi ottenere gli URL desiderati. Tuttavia, come già menzionato, non puoi esportare i dati estratti direttamente in file, ma devi copiarli e incollarli in altri sistemi manualmente.
7. Link Klipper
Link Klipper è uno degli estrattori di link più popolari nel Chrome Web Store. È semplice ma potente e ti aiuta a estrarre tutti i link su una pagina web e a esportarli in un file. Puoi trascinare un’area personalizzata sul sito web e raccogliere tutti i link in quest’area in base alle tue esigenze. Tuttavia, puoi esportare tutti i dati estratti solo come file CSV utilizzando questa estensione. Se hai bisogno di archiviare i dati in altri formati per l’analisi dei dati, dovrai dedicare più tempo a convertire il formato da CSV.
8. Beautiful Soup (Python)
Beautiful Soup è una popolare libreria Python per estrarre dati da file HTML e XML. Gestisce bene HTML mal formattati e offre un’API semplice e intuitiva per navigare ed estrarre dati dai documenti HTML. Se sei familiare con la programmazione, può essere un metodo flessibile ed efficace. Ecco un esempio di codice che mostra come Beautiful Soup estrae link da un sito web.
9. Scrapy (Python)
Scrapy è un potente e flessibile framework open-source per il crawling e lo scraping web, scritto in Python. Puoi trovare un set completo di strumenti per l’estrazione dei dati in Scrapy, compresi i link. Uno dei principali vantaggi di Scrapy è la sua capacità di gestire compiti di scraping su larga scala, supportando il crawling distribuito e affrontando efficacemente scenari complessi. Di seguito è riportato un esempio di codice per estrarre link utilizzando Scrapy.
10. Selenium (Vari linguaggi)
Selenium è noto come uno strumento di automazione web utilizzato per testare le applicazioni. Ma può anche essere utilizzato per attività di web scraping. Rispetto ad altre librerie Python, Selenium visualizza il processo di scraping, rendendo più semplice il debug e la verifica dei link estratti. Tuttavia, in termini di velocità di scraping, Selenium potrebbe essere relativamente più lento rispetto a Beautiful Soup o Scrapy, specialmente per attività di scraping su larga scala.
Parole finali
L’estrazione di link gioca un ruolo fondamentale nella ricerca di mercato. Consente la raccolta di dati per ricerche, analisi SEO, generazione di contatti, ecc. Inoltre, supporta la ricerca di mercato e il monitoraggio del marchio, contribuendo a strategie di marketing e sforzi di conformità. Indipendentemente dal settore in cui operi, puoi trarre vantaggio dall’uso di estrattori di link. Speriamo che tu possa trovare gli strumenti di scraping giusti in questo post e migliorare la tua attività con l’aiuto del web scraping.



