Il trimestre scorso, il nostro team di marketing aveva bisogno dei dati sui prezzi dei prodotti da sei piattaforme e-commerce in tre paesi. Abbiamo provato a creare uno scraper personalizzato in Python, che ha smesso di funzionare in una settimana quando due dei siti hanno aggiornato il loro layout. Quell’esperienza ci ha spinti a cercare dei servizi di web scraping affidabili, e la ricerca non è stata così semplice come ci aspettavamo.
Il mercato dei servizi di web scraping è cresciuto in modo drammatico. Ora ci sono dozzine di opzioni che vanno dagli scraper visivi senza codice a soluzioni complete basate su API, fino a servizi gestiti “chiavi in mano”. I modelli di prezzo variano enormemente: alcuni addebitano per credito API, altri per singola attività, altri per GB di larghezza di banda. E le funzionalità più importanti dipendono interamente dal livello di competenza tecnica del tuo team, dai requisiti di scalabilità e dal budget a disposizione.
Abbiamo trascorso settimane testando e confrontando le opzioni più popolari. Questa guida copre ciò che abbiamo scoperto: i 10 migliori servizi di web scraping nel 2026, suddivisi per tipologia, con pro, contro e prezzi onesti per permetterti di scegliere quello che si adatta davvero al tuo business.
In sintesi: i 10 migliori provider di servizi di web scraping a confronto
| Servizio | Ideale per | Tipologia | Prezzo di partenza |
| Octoparse | Utenti non tecnici e team che necessitano di scraping visivo su larga scala | Senza codice / Self-Service | Gratuito; da 119$/mese |
| ScraperAPI | Sviluppatori che cercano una semplice API per proxy e scraping | API / Self-Service | 49$/mese |
| Bright Data | Infrastrutture proxy di livello enterprise | API + Proxy / Self-Service | Minimo ~500$/mese |
| Apify | Sviluppatori che desiderano actor di scraping preconfigurati | Piattaforma Cloud / Self-Service | 49$/mese |
| ParseHub | Progetti semplici di scraping visivo | Senza codice / Self-Service | 189$/mese |
| Diffbot | Estrazione dati strutturati basata su IA | API / Self-Service | 299$/mese |
| WebScraper | Scraping leggero basato su browser | Estensione / Self-Service | 50$/mese |
| Zyte | Team che utilizzano già il framework Scrapy | Piattaforma Cloud / Self-Service | 9$/unità/mese |
| PromptCloud | Aziende che desiderano una consegna dati completamente delegata | Gestito / Chiavi in mano | Personalizzato |
| Datahut | Progetti di piccole e medie dimensioni che necessitano di estrazione gestita | Gestito / Chiavi in mano | Da 40$/sito |
Cosa sono i servizi di web scraping?
Un servizio di web scraping è una piattaforma, uno strumento o un fornitore di terze parti che automatizza l’estrazione di dati dai siti web e li consegna in formati strutturati come CSV, JSON o Excel. Invece di scrivere e mantenere scraper personalizzati partendo da zero, le aziende utilizzano questi servizi per raccogliere dati web su larga scala, delegando dietro le quinte le parti più complesse, come la rotazione dei proxy, la risoluzione dei CAPTCHA e il rendering di JavaScript.
I casi d’uso comuni includono il monitoraggio dei prezzi sui siti della concorrenza e-commerce, la generazione di lead da directory aziendali, le ricerche di mercato da siti di recensioni, la raccolta di dati accademici e l’alimentazione di dati di addestramento nelle pipeline di IA/Machine Learning.
Tipologie di servizi di web scraping
Prima di immergerci nei singoli strumenti, è utile comprendere le tre categorie principali.
- I servizi Self-service (senza codice) come Octoparse e ParseHub offrono un’interfaccia visiva per puntare, cliccare e configurare i flussi di lavoro di scraping senza scrivere codice. Sono accessibili a marketer, analisti e ricercatori senza il supporto di ingegneri. Il compromesso è che logiche di estrazione molto complesse possono a volte essere più difficili da esprimere visivamente rispetto al codice.
- I servizi Self-service (API / orientati agli sviluppatori) come ScraperAPI, Bright Data e Apify forniscono API e framework di programmazione. Tu scrivi script in Python, JavaScript o altri linguaggi, e il servizio gestisce proxy, rendering del browser e bypass dei sistemi anti-bot (fondamentale quando si cerca di capire come copiare testo da siti protetti). Questi offrono maggiore flessibilità ma richiedono risorse di sviluppo.
- I servizi Chiavi in mano (gestiti) come PromptCloud e Datahut si occupano di tutto. Descrivi quali dati ti servono e il loro team costruisce, esegue e mantiene gli scraper per te. Ricevi dati puliti in base a una pianificazione. Questa è l’opzione che richiede meno sforzo, ma è anche la più costosa, e sacrifichi il controllo sulla logica di estrazione.
Caratteristiche chiave da valutare
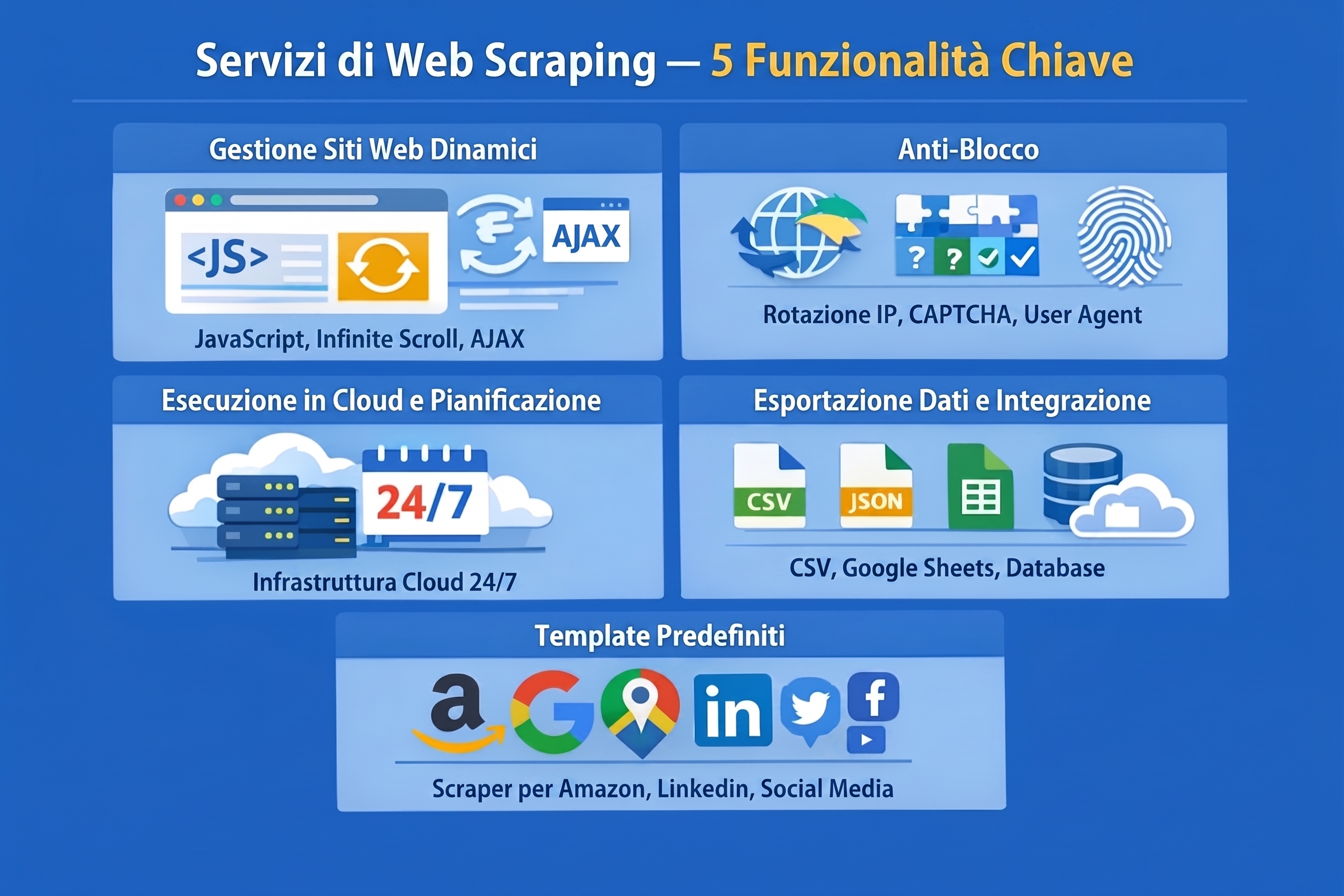
Quando si confrontano i servizi di web scraping, queste sono le capacità che separano gli strumenti affidabili da quelli che ti frustreranno già dal primo mese:
- Gestione di siti web dinamici: La maggior parte dei siti web moderni carica i contenuti con JavaScript, scorrimento infinito e richieste AJAX. Qualsiasi servizio degno di considerazione deve avere un motore browser integrato per renderizzare queste pagine. Se può analizzare solo HTML statico, perderai dati sulla maggior parte dei siti commerciali.
- Capacità anti-blocco: La rotazione degli IP, la risoluzione dei CAPTCHA, la randomizzazione dello user-agent e il browser fingerprinting sono requisiti minimi non negoziabili per qualsiasi progetto di scraping serio. Senza questi, verrai bloccato in poche ore su siti protetti come Amazon o LinkedIn.
- Esecuzione in cloud e pianificazione: Eseguire scraper sulla tua macchina locale va bene per un test rapido, ma i carichi di lavoro in produzione necessitano di un’infrastruttura cloud. Cerca l’esecuzione in cloud 24/7, una pianificazione flessibile (oraria, giornaliera, settimanale) e l’elaborazione simultanea per gestire i lavori di grandi dimensioni più velocemente.
- Esportazione dati e integrazione: Ottenere i dati dovrebbe essere facile, che tu voglia estrarre link da pagina web o esportare interi cataloghi. Come minimo, vorrai esportazioni in CSV, Excel e JSON. I servizi migliori offrono l’integrazione diretta con Google Sheets, database (MySQL, PostgreSQL), archiviazione cloud (S3) e piattaforme di automazione come Zapier.
- Modelli preimpostati: Per obiettivi popolari come Amazon, Google Maps, LinkedIn e le piattaforme di social media, i modelli predefiniti o “actor” fanno risparmiare ore di configurazione. L’ampiezza e la qualità della libreria di modelli di un servizio sono forti elementi di differenziazione.
I 10 migliori servizi di web scraping nel 2026
1. Octoparse: il migliore in assoluto per il web scraping senza codice
Octoparse è diventato silenziosamente uno dei provider e piattaforme di web scraping senza codice più capaci sul mercato. Combina un costruttore di flussi di lavoro visivo punta-e-clicca con un’infrastruttura seria — esecuzione in cloud, rotazione degli IP, risoluzione dei CAPTCHA, e oltre 469 modelli di scraping preconfigurati — in un pacchetto che non ti richiede di scrivere una singola riga di codice.
Ciò che distingue Octoparse dagli altri scraper senza codice è quanto oltre puoi spingerti prima di colpire un muro. Il designer visivo dei flussi di lavoro gestisce impaginazione, scorrimento infinito, menu a tendina, contenuti caricati tramite AJAX e persino pagine protette da login. Quando lo abbiamo testato su un sito e-commerce fortemente dipendente da JavaScript, ha catturato ogni singola scheda prodotto caricata dinamicamente senza alcuna configurazione manuale, oltre a cliccare sugli elementi che desideravamo.
Punti di forza principali:
- Oltre 665 modelli preconfigurati per siti web popolari, inclusi Amazon, Google Maps, TikTok, LinkedIn e dozzine di altri. Inserisci alcuni parametri e inizia a estrarre immediatamente, senza bisogno di configurare il flusso di lavoro.
- Suite anti-blocco completa: Proxy residenziali integrati, rotazione degli IP automatica, risoluzione dei CAPTCHA e randomizzazione del browser fingerprinting. Non hai bisogno di cercare o gestire pool di proxy esterni.
- Estrazione in cloud 24/7 con pianificazione delle attività a intervalli di minuti, ore, giorni o settimane. I tuoi scraper vengono eseguiti sui server di Octoparse, non sulla tua macchina.
- Esportazione flessibile dei dati: CSV, Excel, JSON, HTML, XML, oltre a esportazioni dirette verso Google Sheets, MySQL, PostgreSQL e Amazon S3.
- Accesso API per integrare i dati estratti nelle tue applicazioni e automatizzare i flussi di lavoro.
- Capacità RPA (Robotic Process Automation) per compiti che vanno oltre la pura estrazione dati: compilazione di moduli, clic attraverso processi multi-fase.
- Analisi VOC (Voice-of-Customer): una funzionalità unica che estrae e struttura i dati delle recensioni dei clienti per l’analisi del sentiment.
Dove Octoparse brilla davvero è nell’equilibrio tra facilità d’uso e potenza. Un analista di marketing con zero esperienza di programmazione può impostare un’attività di scraping complessa in meno di 30 minuti utilizzando il costruttore visivo. Allo stesso tempo, un team di dati che esegue centinaia di attività cloud pianificate non esaurirà le potenzialità della piattaforma: il piano Professional supporta fino a 20 processi cloud simultanei.
Sono rimasto onestamente sorpreso dalla libreria di modelli. Avevamo bisogno dei dati dei profili TikTok per un audit sui social media e, invece di costruire un flusso di lavoro personalizzato, abbiamo scelto un modello preconfigurato, inserito gli URL dei profili e ottenuto dati strutturati in pochi minuti. È un vero risparmio di tempo per i team che gestiscono molteplici fonti di dati.
| Piano | Prezzo | Attività | Processi Cloud |
| Gratuito | 0$ | 10 | Solo locale |
| Standard | 119$/mese | 100 | 3–6 |
| Professional | 299$/mese | 250 | Fino a 20 |
| Enterprise | Personalizzato | 750+ | Personalizzato |
Sono disponibili componenti aggiuntivi come proxy residenziali (3$/GB) e risoluzione dei CAPTCHA (1$–1,50$ per mille) se i tuoi progetti colpiscono siti pesantemente protetti.
Una cosa da tenere a mente: la prima volta che apri il costruttore visivo dei flussi di lavoro, c’è una curva di apprendimento. L’interfaccia è potente ma densa. Consiglierei di guardare un video tutorial prima del tuo primo vero progetto—Octoparse ha una solida libreria di guide passo-passo. Dopo le prime due o tre attività, tutto diventa intuitivo.
In sintesi: Se il tuo team necessita di web scraping affidabile e su larga scala senza scrivere codice, Octoparse è l’opzione più solida nel 2026. La combinazione di costruzione visiva del flusso di lavoro, un’enorme libreria di modelli, sistemi anti-blocco integrati e infrastruttura cloud a un prezzo competitivo è difficile da battere.
2. ScraperAPI: il migliore per sviluppatori che cercano una semplice integrazione API
ScraperAPI è un proxy di scraping orientato agli sviluppatori che gestisce la rotazione degli IP, il rendering del browser e la risoluzione dei CAPTCHA tramite una semplice chiamata API. Tu invii un URL; lui restituisce l’HTML. La semplicità è il suo punto di forza: non c’è un costruttore visivo, né un designer di flussi di lavoro, solo un’API pulita che puoi integrare in qualsiasi progetto Python, JavaScript, PHP o Ruby con una singola riga di codice.
Punti di forza principali:
- API semplice: un endpoint, una chiave API, aggiungi l’URL di destinazione come parametro
- Rotazione dei proxy automatica utilizzando proxy residenziali, datacenter e mobili
- Rendering JavaScript per pagine dinamiche
- Gli endpoint per dati strutturati per siti popolari (Amazon, Google, ecc.) restituiscono JSON pre-analizzati
- Funzionalità DataPipeline per pianificare e gestire i lavori di scraping senza codice
Prezzi:
| Piano | Prezzo | Crediti API |
| Hobby | 49$/mese | 100.000 |
| Startup | 149$/mese | 1.000.000 |
| Business | 299$/mese | 3.000.000 |
Considerazioni: ScraperAPI è un eccellente livello di proxy e rendering, ma devi comunque scrivere la tua logica di analisi per estrarre campi dati specifici dall’HTML restituito. Se sei uno sviluppatore, va bene. Se sei un utente non tecnico, questa non è la scelta giusta: saresti servito meglio dall’approccio visivo di Octoparse, che gestisce sia il recupero che l’estrazione dati in un’unica interfaccia.
3. Bright Data: il migliore per infrastrutture proxy di livello Enterprise
Bright Data è il gigante indiscusso del settore dei dati web. Con oltre 150 milioni di IP residenziali, API di scraper preconfigurati per oltre 120 domini, un browser di scraping compatibile con Puppeteer e Playwright, e dataset pronti all’uso, è la piattaforma più completa disponibile. È anche la più complessa da navigare e la più costosa.
Punti di forza principali:
- La più grande rete proxy del settore (oltre 150 milioni di IP residenziali, mobili, ISP, datacenter)
- Web Scraper API con collettori preconfigurati per oltre 120 siti web principali
- Lo Scraping Browser si integra con Playwright e Puppeteer
- Dataset pronti all’uso per e-commerce, immobiliare, lavoro e social media (inclusa la possibilità di scaricare tutte le immagini da un sito per l’addestramento IA)
- Conforme a GDPR e CCPA con rigorosi processi KYC
Prezzi: Basati sul consumo e variano a seconda del prodotto. I prezzi dei proxy vanno da ~3$/GB (datacenter) a 15+$ /GB (residenziali). La Web Scraper API costa tra 1,50$ e 2,50$ per 1.000 richieste. L’utilizzo più significativo parte da circa 500$/mese o più. I piani Enterprise richiedono di contattare il team di vendita.
Considerazioni: Bright Data è potente ma soverchiante per piccoli team. Il modello di prezzo è complesso: devi destreggiarti tra costi proxy per GB, addebiti API per richiesta e potenziali tariffe di calcolo. Per i team che necessitano di scalabilità massiccia e dispongono di risorse ingegneristiche, è difficile da battere. Per tutti gli altri, la curva di apprendimento e la barriera dei costi sono significative. Octoparse offre un punto di ingresso molto più accessibile con prezzi mensili prevedibili e nessuna necessità di gestire l’infrastruttura proxy separatamente.
4. Apify: il miglior marketplace di scraper preconfigurati
Apify gestisce una piattaforma cloud con un marketplace di script di scraping preconfigurati chiamati “Actor”. Ci sono actor per fare scraping su Amazon, Instagram, Google Maps, LinkedIn, per estrarre email da siti web e altre centinaia di piattaforme. Puoi anche creare actor personalizzati in JavaScript o Python.
Punti di forza principali:
- Ampio marketplace con migliaia di actor di scraping ufficiali e creati dalla community
- Sviluppo di actor personalizzati utilizzando JavaScript/Node.js o Python
- Esecuzione in cloud con supporto per browser headless (Puppeteer, Playwright)
- Accesso API per l’automazione dei flussi di lavoro
- Generoso piano gratuito per i test
Prezzi:
| Piano | Prezzo |
| Gratuito | 0$ (limitato) |
| Starter | 49$/mese |
| Scale | 499$/mese |
| Business | 999$/mese |
Considerazioni: Il marketplace di actor di Apify è un punto di forza e una debolezza. La qualità varia: alcuni actor della community smettono di funzionare quando i siti target cambiano, e la manutenzione dipende dall’autore originale. La piattaforma è più orientata agli sviluppatori rispetto agli strumenti senza codice. Se preferisci un flusso di lavoro visivo con modelli affidabili e mantenuti ufficialmente, i 469+ modelli proprietari di Octoparse offrono un’esperienza più coerente.
5. ParseHub: il migliore per progetti semplici di scraping visivo
ParseHub offre un’interfaccia di scraping punta-e-clicca che gestisce siti web dinamici e renderizzati con JavaScript. È simile per concetto a Octoparse, ma con un set di funzionalità più ristretto.
Punti di forza principali:
- Interfaccia visiva, senza codice
- Gestisce il rendering JavaScript e i contenuti dinamici
- Pianificazione e archiviazione basate su cloud
- Esportazioni in CSV, Excel, JSON
Prezzi:
| Piano | Prezzo | Pagine per Esecuzione |
| Standard | 189$/mese | 10.000 |
| Professional | 599$/mese | 10.000+ |
| Enterprise | Personalizzato | Illimitate |
Considerazioni: ParseHub è semplice ma limitato. Manca di risoluzione dei CAPTCHA integrata e di geotargeting, il che significa che ti scontrerai con dei muri su siti pesantemente protetti. Il prezzo è elevato per ciò che ottieni: il piano Standard di Octoparse a 119$/mese include più attività, esecuzione in cloud, funzionalità anti-blocco e una libreria di modelli molto più ampia. ParseHub va bene per progetti leggeri, ma non scala altrettanto bene per carichi di lavoro di produzione.
6. Diffbot: il migliore per l’estrazione dati automatica basata su AI
Diffbot utilizza il machine learning per identificare ed estrarre automaticamente dati strutturati dalle pagine web. Puntalo su una pagina di articolo e restituirà il titolo, l’autore, il testo del corpo e la data di pubblicazione come JSON strutturato, senza alcuna configurazione o impostazione di regole.
Punti di forza principali:
- Estrazione basata su IA: non sono necessari selettori manuali o configurazione dei flussi di lavoro
- Elevata precisione per articoli, prodotti, thread di discussione e pagine profilo
- API Knowledge Graph per il recupero dei dati a livello di entità
- Accesso API batch e in tempo reale
Prezzi:
| Piano | Prezzo | Crediti API |
| Startup | 299$/mese | 250.000 |
| Plus | 899$/mese | 1.000.000 |
| Enterprise | Personalizzato | Personalizzato |
Considerazioni: L’approccio IA di Diffbot funziona bene per tipi di pagine comuni (pagine prodotto, articoli), ma non ti dà alcun controllo quando classifica in modo errato gli elementi o tralascia dei dati. Per progetti in cui hai bisogno di un’estrazione precisa e configurabile — scegliendo esattamente quali campi catturare e come — il selettore visivo di Octoparse ti dà quel controllo pur rimanendo senza codice.
7. WebScraper: la migliore estensione leggera per browser
WebScraper.io è un’estensione per Chrome che ti consente di creare sitemap per navigare ed estrarre dati dai siti web. È gratuito per l’uso locale, con piani cloud a pagamento per la pianificazione e lavori più grandi.
Punti di forza principali:
- Estensione gratuita per Chrome per lo scraping di base
- Logica di estrazione dati basata su sitemap
- Piani cloud per scraping pianificato e automatizzato
- Esportazioni in CSV, Excel, JSON
Prezzi:
| Piano | Prezzo | Crediti Cloud (1 credito = 1 pagina) |
| Project | 50$/mese | 5.000 |
| Professional | 100$/mese | 20.000 |
| Business | 200$/mese | 50.000 |
Considerazioni: WebScraper.io è leggero e conveniente per piccoli lavori, ma fatica con i contenuti dinamici e i siti pesantemente basati su JavaScript. Non ha sistemi anti-blocco integrati, nessuna risoluzione dei CAPTCHA e supporto limitato per interazioni complesse con le pagine. Per qualsiasi cosa vada oltre lo scraping di base, Octoparse offre molte più capacità a un prezzo comparabile — e l’architettura cloud-first è più affidabile per l’uso in produzione.
8. Zyte: il migliore per gli utenti del framework Scrapy
Se il tuo team utilizza già il framework open-source Scrapy, Scrapy Cloud (di Zyte) ti consente di distribuire, pianificare e monitorare i tuoi spider nel cloud. È essenzialmente un hosting cloud per progetti Scrapy con funzionalità aggiuntive di monitoraggio e gestione dei tentativi.
Punti di forza principali:
- Distribuzione diretta per spider Scrapy
- Pianificazione, registrazione e monitoraggio basati su cloud
- Archiviazione ed esportazione dei dati (JSON, CSV, XML)
- Gestione automatica dei tentativi e dei ban
Prezzi: A partire da 9$/unità/mese (1 unità = 1 GB di RAM + 1 crawl simultaneo). Scalare significa aggiungere unità e i costi possono diventare imprevedibili per grandi progetti.
Considerazioni: Questo è rilevante solo se il tuo team ha esperienza con Scrapy. Non c’è alcun costruttore visivo, né modelli. Stai scrivendo e mantenendo spider in Python. Per i team senza sviluppatori dedicati, Octoparse fornisce la stessa esecuzione in cloud e pianificazione con un’interfaccia visiva che non richiede la conoscenza di Python.
9. PromptCloud: il miglior servizio di web scraping completamente gestito
PromptCloud è un servizio “chiavi in mano”: tu dici loro di quali dati hai bisogno e il loro team costruisce, opera e mantiene l’intera pipeline di scraping. Ricevi dati puliti e strutturati in base a una pianificazione tramite API, S3 o altri metodi di consegna.
Punti di forza principali:
- Completamente gestito: non è richiesto alcun coinvolgimento tecnico dal tuo team
- Flussi di lavoro di estrazione personalizzati su misura per le tue esigenze
- Infrastruttura scalabile per la raccolta continua di dati ad alto volume
- Molteplici formati e metodi di consegna dei dati
- Assistenza clienti dedicata
Prezzi: Solo personalizzati, basati sull’ambito del progetto, sul volume dei dati e sulla frequenza. Aspettati costi significativamente più alti rispetto agli strumenti self-service.
Considerazioni: PromptCloud non accetta richieste di scraping una tantum; si concentrano su flussi di dati continui. Se desideri un maggiore controllo sulla tua logica di estrazione e non vuoi fare affidamento su terze parti per ogni aggiustamento, uno strumento self-service come Octoparse ti dà quell’autonomia pur rimanendo accessibile agli utenti non tecnici.
10. Datahut: il miglior servizio gestito per progetti più piccoli
Datahut offre un web scraping gestito con un processo di garanzia della qualità a doppio livello (controlli macchina + umani). Sono più accessibili di PromptCloud per progetti più piccoli o una tantum.
Punti di forza principali:
- Estrazione gestita con garanzia di precisione
- Consegna flessibile tramite API, FTP, S3, Dropbox o email
- Soluzioni specializzate per dati e-commerce e immobiliari
- A partire da 40$/sito per estrazioni di base
Prezzi: Basati sull’utilizzo, a partire da 40$ per sito web. Prezzi personalizzati per progetti più grandi ed esigenze aziendali.
Considerazioni: Ottimo per i team che non possono davvero investire tempo nella configurazione dello scraping. Ma a 40$ per sito con prezzi personalizzati che aumentano rapidamente, potresti eseguire il piano Standard di Octoparse a 119$/mese ed estrarre dati da 100 siti diversi da solo, con il pieno controllo su cosa estrai e quando.
Self-service vs gestito: quale scegliere?
- Scegli il self-service (senza codice) se hai membri del team che possono dedicare da 30 minuti a un’ora per imparare uno strumento di scraping visivo. Octoparse è l’opzione più forte qui: la sua libreria di modelli significa che molte attività richiedono una configurazione quasi nulla, e il costruttore visivo gestisce il resto.
- Scegli il self-service (API) se il tuo team ha sviluppatori che preferiscono scrivere codice e desiderano un controllo granulare sulla gestione delle richieste. ScraperAPI e Apify sono scelte solide, a seconda che tu voglia ritorni HTML grezzi o script di scraping preconfigurati.
- Scegli il gestito/chiavi in mano se le tue esigenze di dati sono altamente specializzate, il tuo volume è enorme e non hai risorse tecniche da assegnare. PromptCloud e Datahut si occupano di tutto, ma paghi un sovrapprezzo per questa comodità.
Per la maggior parte delle aziende, una soluzione self-service senza codice come Octoparse rappresenta il compromesso ideale: abbastanza potente per l’uso in produzione, abbastanza accessibile per i non sviluppatori e con un prezzo sufficientemente prevedibile da poter essere inserito a budget.
Checklist per la decisione finale
Prima di impegnarti in qualsiasi servizio di web scraping, testalo rispetto a questi criteri:
- Puoi iniziare velocemente? Usa il piano gratuito o la prova. Se non riesci a completare un’attività di scraping di base entro un’ora, lo strumento è troppo complesso per il tuo team.
- Gestisce i tuoi siti di destinazione? Testa sui siti web effettivi da cui devi estrarre dati, in particolare quelli pesantemente basati su JavaScript o protetti da sistemi anti-bot.
- Sono disponibili modelli per i tuoi obiettivi? I modelli preconfigurati per siti come Amazon, Google Maps o LinkedIn possono ridurre il tempo di configurazione da ore a minuti. La libreria di Octoparse con oltre 469 modelli è la più grande tra gli strumenti senza codice.
- L’anti-blocco è integrato? Non dovresti aver bisogno di cercare e gestire i tuoi proxy separatamente. Rotazione degli IP integrata, risoluzione dei CAPTCHA e gestione del fingerprinting dovrebbero essere requisiti minimi.
- Può scalare con te? L’esecuzione in cloud, l’elaborazione simultanea e la pianificazione sono essenziali per i carichi di lavoro in produzione. Assicurati che il servizio non diventi un collo di bottiglia man mano che le tue esigenze di dati crescono.
- Il prezzo è trasparente? Sappi esattamente per cosa stai pagando: per attività, per credito, per GB. I prezzi mensili prevedibili (come il modello di abbonamento di Octoparse) sono più facili da preventivare rispetto alla fatturazione basata sui consumi che fluttua in modo selvaggio.
Il servizio di web scraping giusto dipende dal tuo team, dal tuo livello di comfort tecnico e dai tuoi obiettivi relativi ai dati. Ma se dovessimo raccomandare un punto di partenza per la maggior parte delle aziende nel 2026, sarebbe Octoparse. Iscriviti al piano gratuito, testa alcuni modelli sui tuoi siti di destinazione ed esegui il tuo primo scraping in cloud. Saprai in un’ora se è la scelta giusta.
Domande frequenti
- Qual è il miglior servizio di web scraping per principianti?
Octoparse è la scelta migliore per i principianti. La sua interfaccia visiva punta-e-clicca non richiede codice, e la libreria di oltre 469 modelli preconfigurati ti consente di estrarre dati da siti popolari semplicemente inserendo un URL e pochi parametri. Il piano gratuito ti dà 10 attività per fare dei test prima di passare a un piano superiore.
- I servizi di web scraping possono bypassare i CAPTCHA?
Sì — la maggior parte dei servizi di livello professionale include la risoluzione dei CAPTCHA. Octoparse, ScraperAPI e Bright Data gestiscono i CAPTCHA automaticamente. Strumenti di base come WebScraper.io e ParseHub generalmente non lo fanno, il che significa che verrai bloccato sui siti protetti.
- Qual è la differenza tra un’API di scraping e uno scraper senza codice?
Un’API di scraping (come ScraperAPI) restituisce HTML grezzo che poi analizzi con il tuo codice. Uno scraper senza codice (come Octoparse) gestisce sia il recupero della pagina che l’estrazione di campi dati specifici attraverso un’interfaccia visiva — nessun codice è necessario in alcuna fase.
- Il web scraping è legale?
Il web scraping di dati disponibili pubblicamente è generalmente legale, ma i dettagli dipendono dai termini di servizio del sito web, dal tipo di dati raccolti e dalla giurisdizione. Normative come il GDPR limitano lo scraping di dati personali nell’UE. Rivedi sempre il file robots.txt e i termini di servizio di un sito e consulta una consulenza legale per progetti sensibili.
- Quanto costa il web scraping?
I costi vanno dal gratuito (piano gratuito di Octoparse, estensione Chrome di WebScraper.io) a migliaia di dollari al mese (piani enterprise di Bright Data, servizi gestiti come PromptCloud). Per la maggior parte delle aziende di medie dimensioni, 100$–300$/mese coprono uno scraping di livello produttivo con uno strumento self-service. Il piano Standard di Octoparse a 119$/mese è un punto di partenza molto comune.