Ci sei passato anche tu. Hai finalmente avviato lo scraper, estratto migliaia di record dal web, aperto il file di esportazione e… è un disastro. È qui che entra in gioco la pulizia dei dati.
Il testo delle recensioni è aggrovigliato con tag HTML. Le date appaiono in tre formati diversi — a volte quattro. Metà delle voci sono duplicati. C’è spam mescolato ai feedback reali dei clienti. E in qualche modo, una colonna che dovrebbe contenere i prezzi presenta la parola “null” a righe alterne.
Questa è la parte della pulizia dei dati di cui nessuno ti avverte quando ti vendono l’idea delle “decisioni basate sui dati”. Lo scraping è la parte facile. Pulire i dati — renderli coerenti, accurati e realmente utilizzabili — è dove inizia il vero lavoro.
E non è un problema da poco. Secondo il sondaggio State of Data Science 2020 di Anaconda condotto su oltre 2.300 professionisti, gli intervistati trascorrono circa il 45% del loro tempo nel caricamento e nella pulizia dei dati, rendendola la parte del lavoro che richiede più tempo in assoluto. Non l’analisi. Non le intuizioni. Solo portare i dati in uno stato in cui l’analisi sia anche solo possibile.
Se hai effettuato la pulizia dei dati a mano — o peggio, assumendo sviluppatori per scrivere script usa e getta per ogni progetto — sai già che non è sostenibile. La domanda è: qual è l’alternativa?
Di questo parla questo articolo. Analizzeremo in dettaglio cosa comporta effettivamente la pulizia dei dati, perché gli strumenti tradizionali si rivelano inadeguati per i dati estratti dal web e come Octoparse combina l’intelligenza artificiale con regole configurabili per gestire la parte più caotica di qualsiasi progetto sui dati, senza scrivere una sola riga di codice.
Cos’è la Pulizia dei Dati e la Normalizzazione Database: Perché Richiedono Così Tanto Tempo?
Scendiamo nei dettagli, perché il termine “pulizia dei dati” viene usato spesso senza che nessuno spieghi cosa significhi realmente nella pratica.
La pulizia dei dati (chiamata anche data cleansing o data scrubbing) è il processo di rilevamento e correzione di errori, incongruenze e problemi di qualità in un set di dati affinché sia abbastanza affidabile da essere utilizzato per l’analisi o il processo decisionale.
Sembra semplice. Non lo è.
Quando si lavora con dati estratti dal web — presi da siti e-commerce, piattaforme social, directory o portali di contenuti — la pulizia comporta tipicamente cinque sfide distinte:
Standardizzazione dei dati e dei formati. La stessa informazione appare completamente diversa a seconda della fonte. Una data potrebbe apparire come “04/23/2023” su un sito, “23-04-2023” su un altro e “23 Aprile 2023” su un terzo. Un prezzo potrebbe essere “$29.99”, “29.99 USD” o “29,99 €”. Senza un’adeguata standardizzazione dei dati, le tue informazioni sono impossibili da confrontare o aggregare.
Eliminazione del rumore. I dati grezzi estratti spesso arrivano avvolti in tag HTML, incorporati con caratteri speciali o disordinati con spazi vuoti e artefatti di formattazione. Una recensione di un prodotto che dovrebbe recitare “Ottimo prodotto” in realtà appare come <p class="review-text"><b>Ottimo prodotto!!!</b></p> nella tua esportazione. Quel rumore deve sparire.
Rimozione dei duplicati. Quando esegui lo scraping di più pagine — o della stessa pagina nel tempo — i duplicati si insinuano ovunque. A volte sono copie esatte. Più spesso, sono quasi-duplicati con sottili differenze (uno spazio finale, un timestamp leggermente diverso) che li rendono difficili da intercettare con una semplice deduplicazione.
Filtraggio della spazzatura. Non tutte le informazioni estratte meritano di essere conservate. Commenti spam, recensioni generate da bot, annunci mascherati da contenuti, voci di test — tutti questi inquinano il tuo dataset. Identificarli e rimuoverli, effettuando una corretta scrematura database, richiede molto più di una semplice corrispondenza di parole chiave.
Gestione dei valori mancanti. I dati del mondo reale presentano delle lacune. A un annuncio di prodotto potrebbe mancare il prezzo. Una recensione potrebbe non avere la data. Decidere come gestire queste lacune — riempirle, segnalarle o rimuovere completamente il record — è una scelta soggettiva che dipende dal tuo caso d’uso.
Pensa alla pulizia dei dati come alla raffinazione del petrolio greggio. Lo hai estratto dal suolo (scraping), ma non puoi mettere il petrolio greggio nella tua auto. Ha bisogno di essere processato, filtrato e raffinato prima di diventare qualcosa di utile. La pulizia dei dati è quel passaggio di raffinazione.
In sintesi: Se salti la pulizia dei dati o la fai male, ogni analisi basata su quei dati sarà inaffidabile. È la base. Sbaglia questa, e tutto ciò che viene dopo vacillerà. Secondo la ricerca di Gartner del 2020 sulle soluzioni per la qualità dei dati, una scarsa qualità dei dati costa alle organizzazioni in media 12,9 milioni di dollari all’anno. E Thomas C. Redman, scrivendo sulla MIT Sloan Management Review, stima che i dati errati costino alla maggior parte delle aziende dal 15% al 25% delle entrate.
Perché la Maggior Parte degli Strumenti di Pulizia dei Dati Non È Stata Progettata per Questo
Qui le cose diventano frustranti. Non mancano gli strumenti per la pulizia dei dati in circolazione, dalle funzioni integrate di Excel alle piattaforme ETL dedicate come Talend o Alteryx. Quindi perché pulire i dati web estratti sembra ancora così doloroso?
Perché la maggior parte degli strumenti di pulizia dei dati è stata progettata per dati strutturati che risiedono già nei database. Presumono che i tuoi dati arrivino in colonne prevedibili con formati perlopiù prevedibili. I dati estratti dal web infrangono ognuna di queste presunzioni.
Il problema del caos dei formati. Quando estrai dati da Amazon, eBay, Twitter e YouTube contemporaneamente, hai a che fare con strutture dati, formati di data, standard di codifica e layout dei campi estremamente diversi. Gli strumenti tradizionali si aspettano che tu scriva regole di trasformazione per ogni singola fonte, e che le riscriva ogni volta che un sito web aggiorna il suo HTML.
Il problema della scalabilità. Pulire qualche centinaio di righe in Excel è gestibile. Pulire 500.000 record da sei piattaforme diverse? Excel va in crash. Gli approcci di scripting tradizionali (Python pandas, trasformazioni SQL) funzionano ma richiedono uno sviluppatore, tempi di test e manutenzione ogni volta che la struttura dei dati cambia.
Il problema dell’intelligenza. La pulizia basata su regole è potente, ma rigida. Un pattern regex che elimina i tag HTML non intercetterà le recensioni spam. Una regola di deduplicazione che cerca stringhe esatte non troverà i quasi-duplicati. Finisci per aver bisogno di strati di regole, ognuna creata a mano, e che comunque mancano casi limite che un essere umano noterebbe all’istante.
Questo è il divario. I dati estratti dal web necessitano di un approccio alla pulizia che sia abbastanza flessibile da gestire formati imprevedibili, abbastanza intelligente da individuare problemi che le sole regole ignorerebbero, e abbastanza accessibile da non richiedere un team di ingegneria dei dati per essere configurato.
L’Approccio Ibrido: Quando l’IA Incontra le Regole Configurabili
Il team di ingegneria di Octoparse ha trascorso anni a lavorare con i dati web più disordinati immaginabili: esportazioni e-commerce multipiattaforma, feed di social media multilingua, dataset di contenuti interregionali. E sono giunti a una conclusione che col senno di poi potrebbe sembrare ovvia:
Né l’IA da sola né le regole da sole risolvono il problema della pulizia dei dati. Hai bisogno di entrambe, che lavorino insieme.
Pensala come una cucina con due chef. Lo chef IA ha un istinto geniale: può assaggiare un piatto e identificare istantaneamente cosa non va, suggerire quali spezie aggiungere e individuare ingredienti avariati che nessun altro ha notato. Lo chef delle regole è preciso e costante: segue le ricette alla perfezione, pesa gli ingredienti al grammo e produce lo stesso risultato ogni volta.
Separatamente, ognuno ha dei punti deboli. Lo chef IA improvvisa troppo; lo chef delle regole non sa adattarsi. Insieme, coprono i rispettivi punti ciechi.
Questa è la filosofia alla base del motore di pulizia dei dati di Octoparse. Oggi, il livello IA alimenta la generazione intelligente di regex e l’estrazione semantica delle entità: comprende i tuoi dati e scrive i pattern di pulizia per te. Il livello basato su regole gestisce il lavoro di precisione: trasformazioni regex, standardizzazione del formato della data, transcodifica HTML, deduplicazione ed estrazione dei campi. Entrambi operano all’interno di un’interfaccia visiva dove puoi configurarli, regolarli e combinarli senza scrivere codice.
E Octoparse sta attivamente espandendo il livello IA. Funzionalità come l’analisi del sentiment, il rilevamento dello spam e il riconoscimento avanzato delle anomalie sono già disponibili tramite i servizi dati di Octoparse — e sono in programma per l’integrazione diretta nel prodotto. Le fondamenta sono state costruite; l’intelligenza continua a crescere.
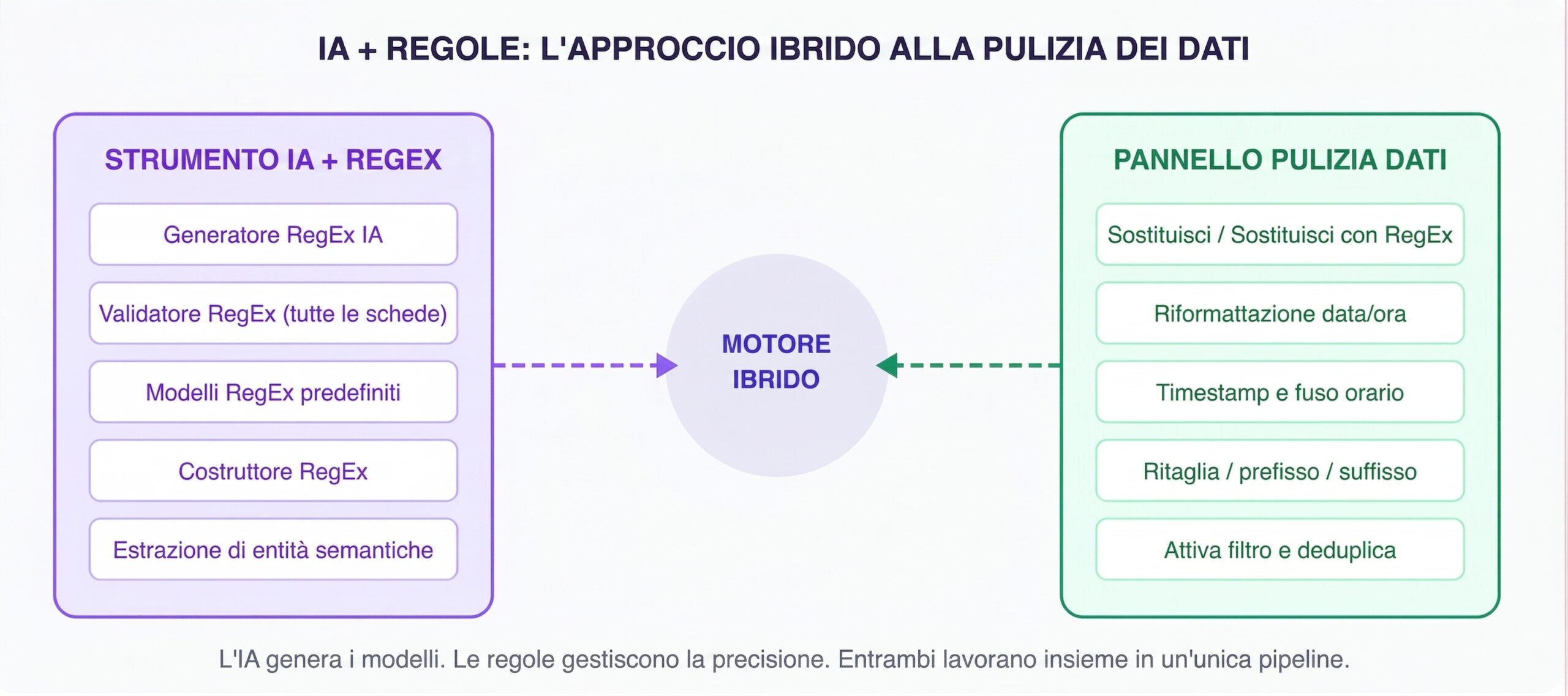
Il motore ibrido: l’IA gestisce l’intelligenza, le regole gestiscono la precisione — entrambi controllati tramite un’interfaccia visiva senza codice.
Tre Livelli di Potenza per la Pulizia dei Dati — Zero Righe di Codice
Scendiamo nel concreto. Ecco come si presenta nella pratica il toolkit di pulizia dei dati di Octoparse, suddiviso nei tre livelli che gestiscono diversi tipi di sfide di pulizia.
Abbinamento Intelligente dei Pattern con RegEx (Nessuna Laurea Richiesta)
Le espressioni regolari (regex) sono i cavalli di battaglia della pulizia dei dati basata su testo. Ti permettono di trovare e trasformare pattern nei tuoi dati: estrarre ID prodotto da stringhe disordinate, riformattare numeri di telefono, estrapolare valori di prezzo, rimuovere caratteri speciali.
Il problema? Scrivere regex è sempre stato un ostacolo in termini di competenze. Un pattern come (\d{2})/(\d{2})/(\d{4}) sembra codice alieno se non ci hai mai lavorato prima.
Octoparse risolve questo problema con un triplice approccio:
- Generatore RegEx IA. Inserisci fino a 5 campioni di testo nel campo Test String, quindi trascina il cursore per evidenziare le corrispondenze previste: le porzioni esatte che desideri estrarre. Clicca su “AI Generate” e l’IA analizza le tue selezioni per produrre un pattern regex funzionante. Nessuna conoscenza della sintassi richiesta. Ad esempio, incolli tre stringhe di prodotto come “ID Prodotto: ABC12345”, evidenzi solo la porzione ID in ciascuna e l’IA genera un pattern affidabile che funziona su tutto il tuo dataset. Verificalo nel validatore sottostante, quindi premi “Save” per applicarlo.
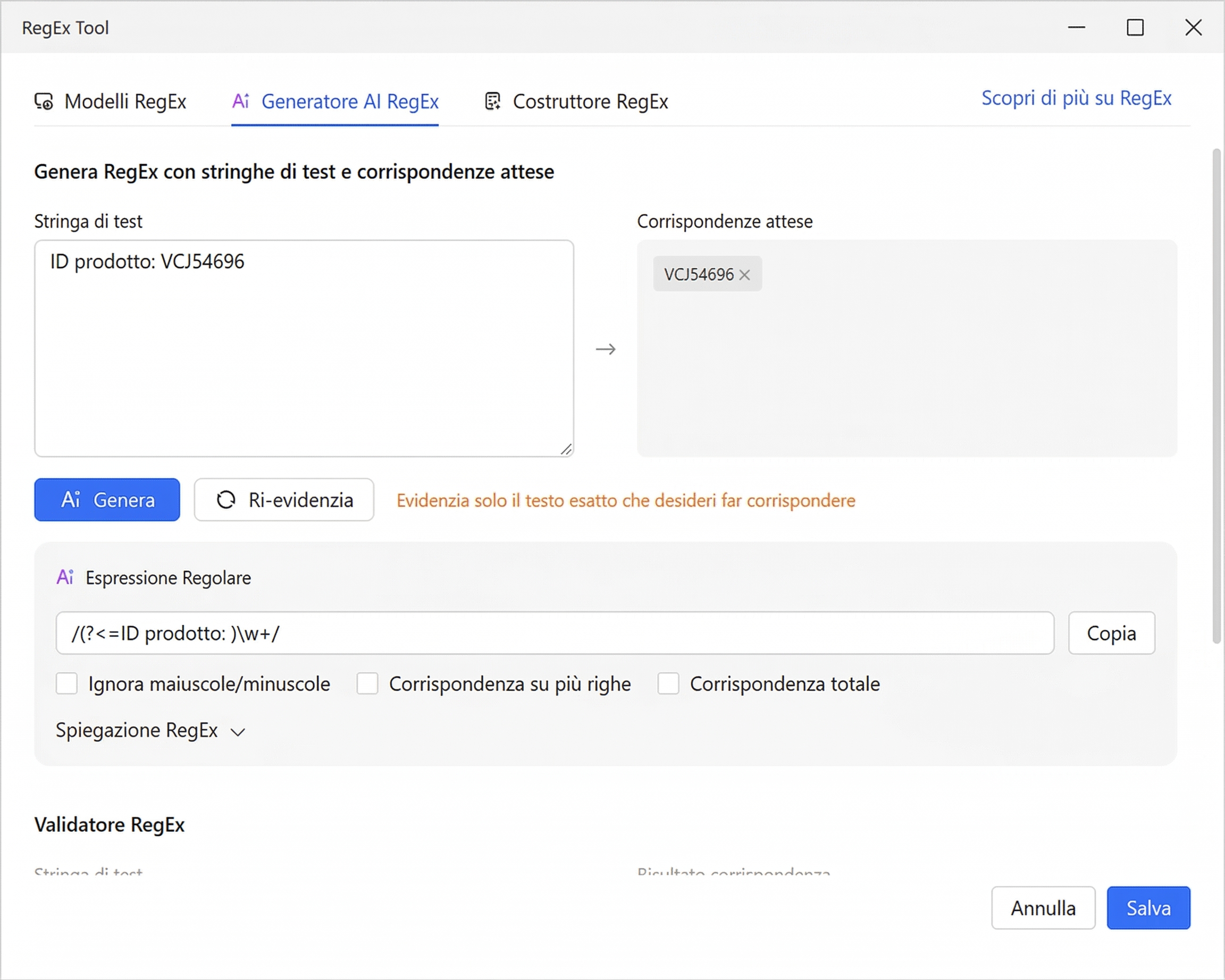
- Pattern RegEx. Octoparse include una libreria di pattern regex predefiniti per le attività di estrazione più comuni: Indirizzo Email Comune, URL/Indirizzo Web, Numero di Telefono USA, CAP USA, Data (formato AAAA-MM-GG), Numero Intero, Numero a Virgola Mobile, Spazi Vuoti Finali e Nuova Riga, Caratteri Alfabetici e altro ancora. Selezionane uno dal menu a tendina e applicalo con un clic.
- Costruttore RegEx (RegEx Builder). Per estrazioni mirate, il costruttore ti consente di generare regex utilizzando regole di corrispondenza: “Match by Start” (con un’opzione “Include Start”), “Match with End” (con “Include End”) e “Matched by Content” (“Contains One”). Imposta le tue condizioni, clicca su “Generate” e costruirà la regex per te, senza dover scrivere manualmente la sintassi.
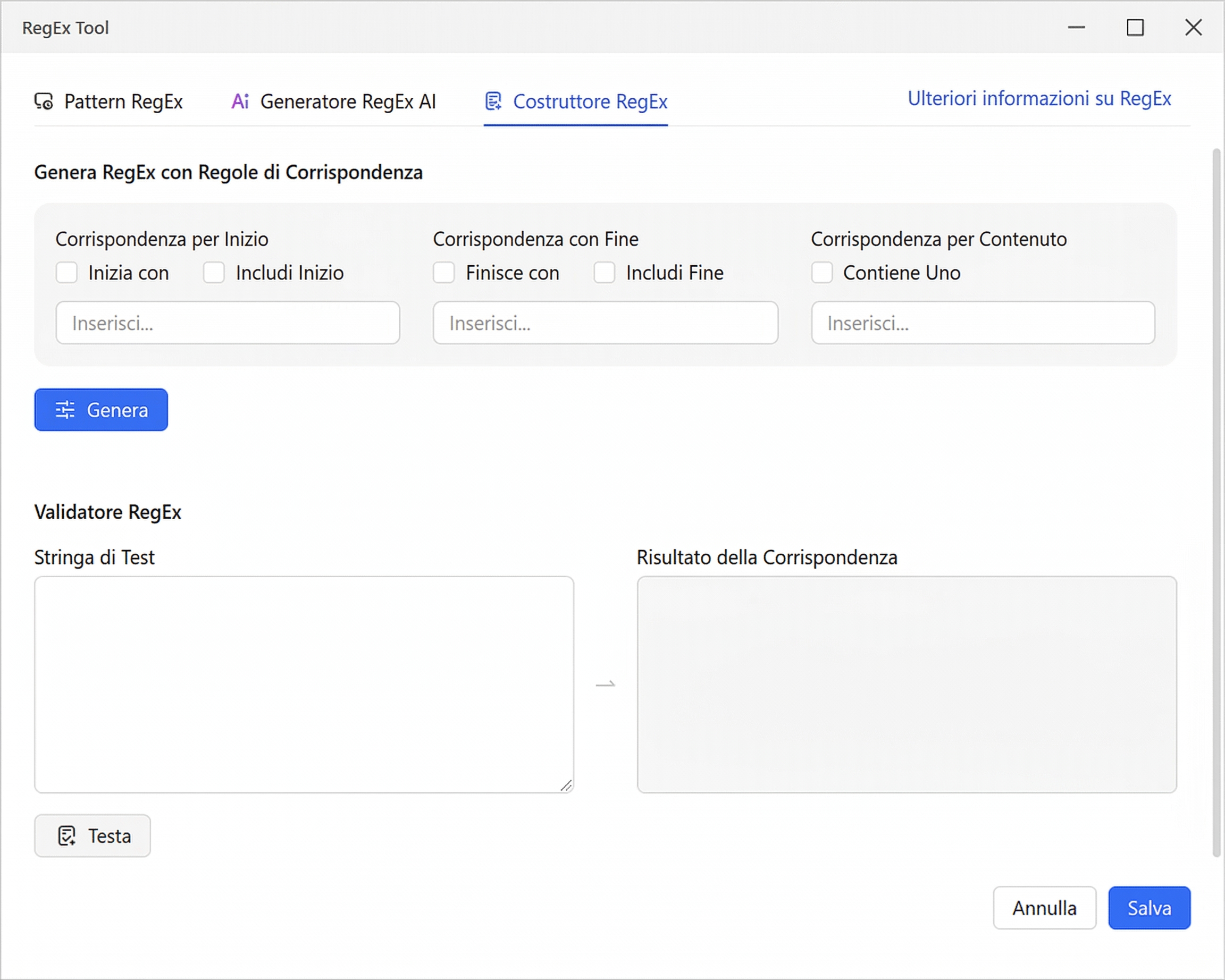
Tutte e tre le schede includono un Validatore RegEx integrato con i campi Test String e Matching Result, in modo da poter verificare qualsiasi pattern prima di applicarlo ai tuoi dati.
Esempio reale: Hai estratto degli annunci di prodotti e il campo del prezzo contiene stringhe disordinate come “Prezzo: $29.99 USD” mescolate a “Da $25.00”. Invece di scrivere un pattern regex da zero, apri il Generatore RegEx IA, incolli alcune stringhe di esempio nel campo Test String, trascini il cursore per evidenziare solo il prezzo numerico in ciascuna, quindi fai clic su “AI Generate”. L’IA produce un pattern funzionante che estrae valori di prezzo puliti. Verificalo nel Validatore RegEx, premi “Save” e verrà applicato a tutto il tuo dataset.
Standardizzazione di Data e Ora (Uno dei Problemi Più Difficili nei Dati)
Se hai mai unito dataset provenienti da paesi diversi, conosci l’incubo. “04/05/2023” è il 5 aprile o il 4 maggio? Dipende se la fonte è americana o europea. Ora moltiplicalo per una dozzina di fonti di dati attraverso diversi fusi orari, e avrai un serio problema di coerenza.
Octoparse gestisce tutto questo con tre opzioni di pulizia dedicate nel pannello Clean Data:
- Riformattazione di data/ora estratte. Il sistema riconosce i formati di data in entrata — MM/GG/AAAA, GG/MM/AAAA, AAAA-MM-GG, “23 Apr, 2023” — e li converte tutti nel formato standard scelto. Lo configuri una volta e si applica all’intero dataset.
- Conversione del fuso orario. Quando i tuoi dati provengono da fonti in fusi orari diversi (ad esempio, Amazon US contro Amazon UK), questa opzione normalizza i timestamp su un singolo fuso orario in modo che i tuoi confronti basati sul tempo abbiano effettivamente senso.
- Conversione dei timestamp. I timestamp grezzi come “1682294400” diventano date leggibili dall’uomo, rendendo i tuoi dati immediatamente comprensibili senza calcoli manuali.
Pulizia Intelligente Basata sull’IA
Oltre all’abbinamento dei pattern e alla conversione dei formati, il livello IA di Octoparse aggiunge un livello di comprensione che le sole regole non possono eguagliare.
Estrazione semantica delle entità (disponibile ora). È qui che l’IA brilla davvero nel prodotto Octoparse di oggi. Punti e clicchi sul contenuto che vuoi estrarre da testo non strutturato — nomi di prodotti sepolti in paragrafi di recensioni, menzioni di aziende in post social, punti di prezzo incorporati in thread di commenti — e l’IA comprende il significato semantico di ciò che stai selezionando. Genera quindi automaticamente pattern regex che catturano quelle entità in tutto il tuo dataset, organizzandole in campi puliti e separati. Non si tratta solo di abbinamento di pattern: è l’IA che comprende cosa stai cercando e costruisce la logica di estrazione per te.
Analisi del sentiment, rilevamento dello spam e suggerimenti intelligenti di regole (tramite servizi dati, con integrazione nel prodotto in programma). Per i team che necessitano di una pulizia IA più profonda — come etichettare automaticamente il sentiment delle recensioni come positivo, negativo o neutro, segnalare lo spam generato da bot o ottenere regole di pulizia consigliate dall’IA in base al rilevamento delle anomalie — queste funzionalità sono disponibili oggi tramite i servizi dati professionali di Octoparse. Il team di ingegneri le sta attivamente integrando nel prodotto principale, in modo che diventino funzionalità self-service nelle versioni future. L’architettura è già progettata per questo; è solo questione di quando, non di se.
Vederlo in Azione: Pulizia dei Dati delle Recensioni E-Commerce
Esaminiamo uno scenario reale. Hai estratto 50.000 recensioni di prodotti da più piattaforme e-commerce per un progetto di analisi competitiva. Ecco come si presentano i dati grezzi e cosa succede quando il motore di pulizia di Octoparse li elabora.
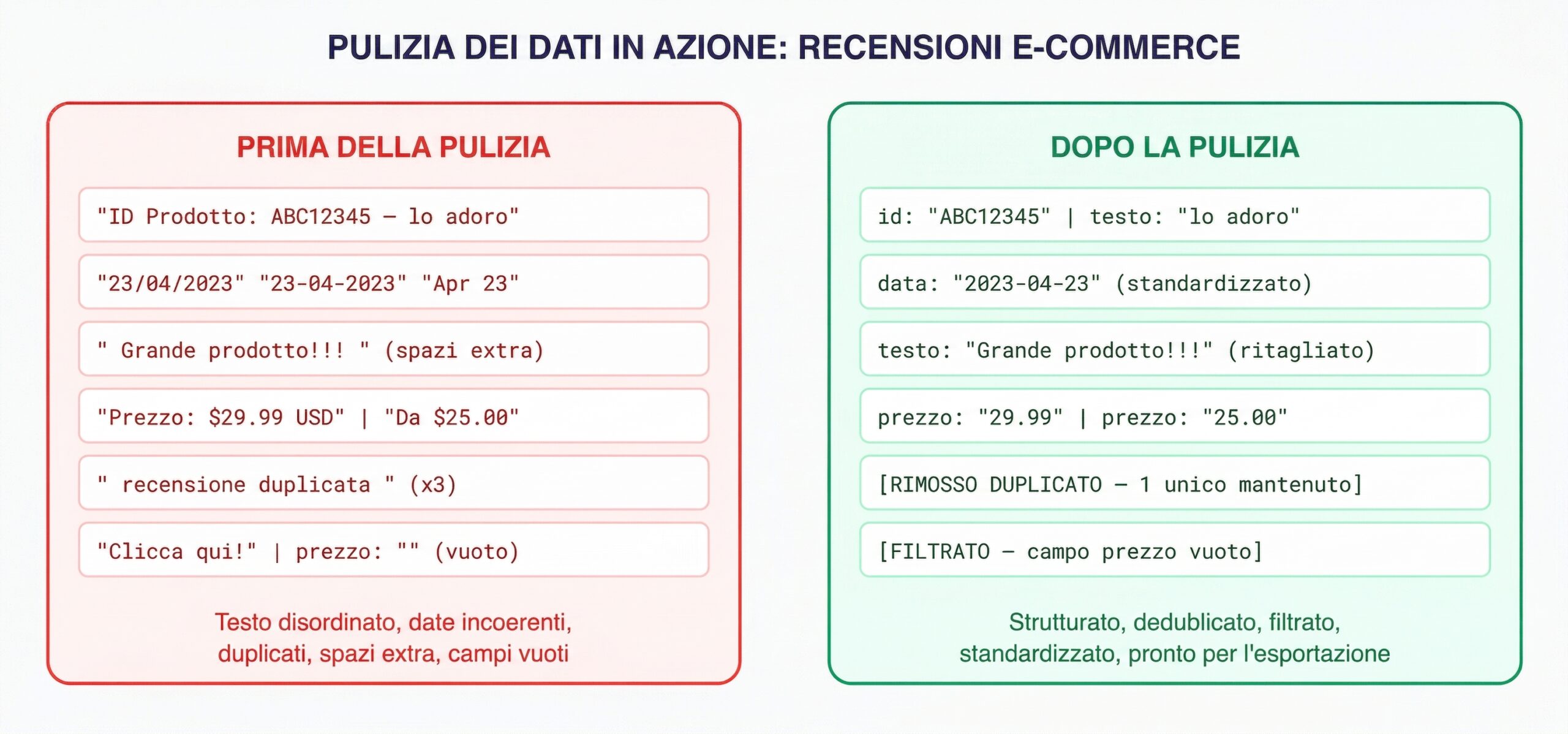
Prima e dopo: i dati disordinati delle recensioni multi-fonte diventano strutturati, deduplicati e pronti per l’analisi.
Ecco come imposteresti tutto questo in Octoparse, passo dopo passo:
- Passaggio 1: Apri gli strumenti di pulizia sul tuo campo dati. All’interno dell’editor di task personalizzati di Octoparse, fai clic con il tasto destro del mouse sul campo dati che desideri pulire. Vedrai l’opzione “Clean Data” nel menu contestuale: cliccala per aprire il pannello di pulizia.
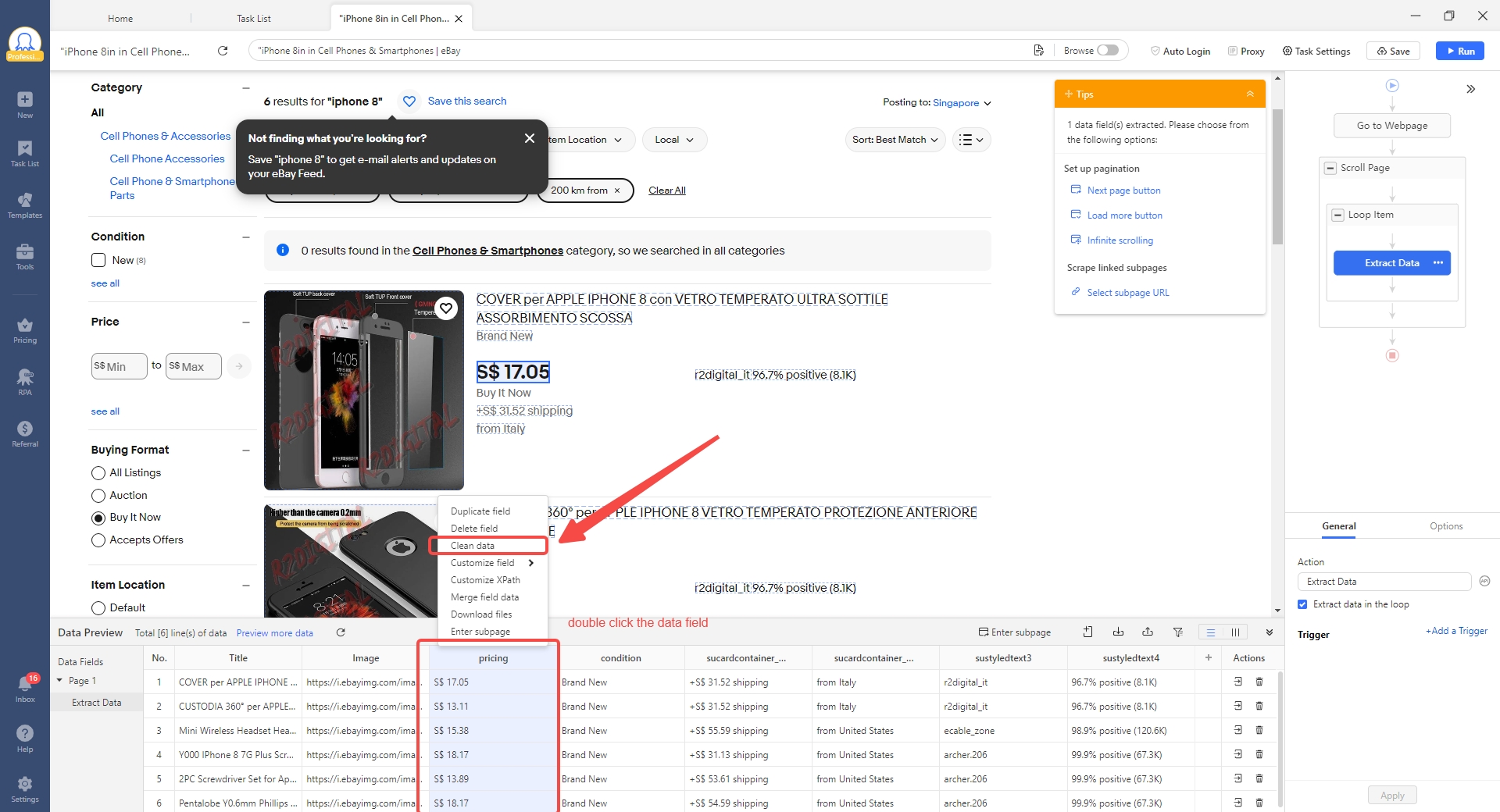
- Passaggio 2: Standardizza i formati delle date. Sul campo review_date, aggiungi un passaggio di pulizia e seleziona “Reformat extracted date/time”. Scegli il formato di destinazione (AAAA-MM-GG). Octoparse rileva automaticamente i formati in entrata e li converte tutti.
- Passaggio 3: Usa la regex IA per estrarre le entità. Hai bisogno di estrarre ID prodotto, nomi di marchi o punti dati specifici dal testo disordinato delle recensioni? Apri il RegEx Tool (nella sezione Tools), passa alla scheda AI RegEx Generator, incolla fino a 5 stringhe di esempio, evidenzia le porzioni target e clicca su “AI Generate”. Verifica il risultato nel RegEx Validator, quindi salva: si applicherà all’intero dataset.
- Passaggio 4: Filtra i dati indesiderati. Usa la funzione Trigger per impostare condizioni che escludono le righe di cui non hai bisogno: ad esempio, escludi le recensioni in cui il campo del prezzo supera una certa soglia, o elimina le righe in cui un campo obbligatorio è vuoto.
- Passaggio 5: Deduplica. Per la deduplicazione su un singolo campo dati, usa la funzione Remove Duplicates all’interno del modulo Data Preview per filtrare i valori duplicati. Per la deduplicazione dell’intero record su tutto il tuo dataset, la funzione di esportazione di Octoparse include un’opzione di dedup integrata che rimuove automaticamente le righe duplicate durante l’esportazione.
- Passaggio 6: Esporta dati puliti. Esegui il task sul cloud. Esporta in Excel, CSV, nel tuo database o tramite API. I 50.000 record disordinati usciranno come un dataset pulito, strutturato e pronto per l’analisi.
Tempo totale di configurazione? Circa 15 minuti.
Confrontalo con l’approccio tradizionale: Uno sviluppatore Python scrive uno script personalizzato con pandas, BeautifulSoup, dateutil e una libreria di analisi del sentiment. I test richiedono un giorno. I casi limite richiedono un altro giorno. Quando il progetto successivo ha fonti di dati diverse, ricominciano da capo. Questa è la differenza tra uno strumento creato appositamente per la pulizia dei dati e un approccio di codifica generico.
In Quali Altri Ambiti È Fondamentale
L’approccio ibrido IA + regole funziona per qualsiasi scenario di pulizia dei dati web. Eccone alcuni che gli utenti di Octoparse gestiscono regolarmente:
Monitoraggio dei prezzi sui marketplace. I prezzi estratti arrivano in ogni formato immaginabile: “$29.99”, “29,99 €”, “£24.99”, “Da $25”. Le regex eliminano il rumore ed estraggono i valori numerici, mentre i filtri catturano anomalie come prezzi palesemente errati (ad esempio, un annuncio di un laptop a $0.01).
Monitoraggio dei brand sui social media. I post da Twitter, Reddit e forum arrivano con formattazioni specifiche della piattaforma, emoji, hashtag e vari gradi di rumore. La pulizia basata su regole elimina gli artefatti di formattazione. La regex potenziata dall’IA estrae entità come nomi di brand e menzioni di prodotti, mentre i pattern regex e i filtri gestiscono la rimozione del rumore. Per analisi più approfondite come la classificazione del sentiment, il team dei servizi dati di Octoparse può impostare pipeline personalizzate.
Generazione di lead dalle directory. Gli elenchi aziendali estratti da Pagine Gialle, LinkedIn e directory di settore contengono formattazioni incoerenti per numeri di telefono, indirizzi e nomi di aziende. Le regex standardizzano i formati, e la funzione Remove Duplicates filtra le voci ripetute in modo che la tua lista finale sia pulita e pronta per il contatto.
Ricerca e aggregazione di contenuti. I metadati video da YouTube, gli articoli dai siti di notizie e i post dei blog da tutto il web necessitano tutti di standardizzazione delle date e deduplicazione prima di essere utili per la ricerca. Il motore ibrido gestisce tutto questo in un’unica pipeline.
Cosa Rende Questo Diverso Dagli Altri Strumenti di Pulizia dei Dati
| Manuale / Excel | Script Python | Strumenti ETL Tradizionali | Motore Ibrido Octoparse | |
| Curva di apprendimento | Bassa | Alta (codifica) | Medio-Alta | Bassa (visiva, no-code) |
| Gestione dati web | Scarsa | Buona (se su misura) | Discreta | Creato appositamente per dati web |
| Capacità IA | Nessuna | Fai-da-te (aggiungi librerie) | Limitata | Generazione regex IA + estrazione semantica (sentiment e NER via servizi dati) |
| Supporto Regex | Di base | Completo (manuale) | Variabile | Generato da IA + libreria + costruttore visivo |
| Riutilizzabilità | Nessuna | Copia-incolla script | Basata su template | Passaggi di pulizia modulari e condivisibili |
| Scalabilità | ~10K righe max | Illimitata (con infrastruttura) | Dipende dalla licenza | Esecuzione in cloud, 500K+ record |
| Tempo di configurazione | Minuti (ma manuale) | Da giorni a settimane | Settimane | Da minuti a ore |
Perché Questo è Importante per il Tuo Prossimo Progetto
Se stai leggendo questo articolo, probabilmente non sei nuovo al mondo dei dati. Conosci il valore di informazioni pulite e strutturate. La domanda non è se la pulizia dei dati sia importante, ma se stai spendendo saggiamente il tuo tempo per farla.
Ogni ora che passi a pulire manualmente i dati è un’ora sottratta all’analisi, alla strategia o al processo decisionale. Ogni settimana che uno sviluppatore trascorre scrivendo script di pulizia usa e getta è una settimana in cui non sta creando funzionalità o prodotti.
Il motore di pulizia ibrido di Octoparse non elimina la necessità della pulizia dei dati: quella necessità non svanirà. Ciò che elimina è il lavoro manuale estenuante. L’IA gestisce l’intelligenza. Le regole gestiscono la precisione. L’interfaccia visiva garantisce l’accessibilità. E il cloud gestisce la scalabilità.
Il risultato: la pulizia dei dati passa dall’essere la più grande perdita di tempo nel tuo flusso di lavoro sui dati a uno dei passaggi più veloci. La configuri una volta, la riutilizzi su più progetti e lasci che il sistema faccia il lavoro pesante.
Iniziare con la Pulizia dei Dati di Octoparse
Pronto a provarlo? Ecco il percorso rapido:
- Crea un account gratuito su octoparse.it. Nessuna carta di credito richiesta. Il piano gratuito include le funzionalità di pulizia dei dati.
- Imposta un task di scraping. Usa il costruttore point-and-click in un task personalizzato per iniziare a estrarre dati dal tuo sito web target.
- Apri gli strumenti di pulizia. Fai clic con il tasto destro su qualsiasi campo dati estratto e seleziona “Clean Data”. Vedrai opzioni come Replace, Replace with Regular Expression, Match with Regular Expression, Trim spaces, Add a prefix/suffix, Reformat extracted date/time, Timestamp conversion, Timezone conversion e HTML transcoding. Per lavori avanzati con le regex, il RegEx Tool nella sezione Tools offre un AI RegEx Generator, RegEx Patterns predefiniti e un RegEx Builder.
- Esegui ed esporta. Esegui sul cloud, programmalo per l’esecuzione automatica ed esporta i dati puliti nel tuo formato preferito: Excel, CSV, database o API. Abilita la deduplicazione all’esportazione per un output automaticamente pulito.
Questo è tutto. Quattro passaggi dai dati web grezzi a un output pulito e strutturato.
Dati Puliti, Decisioni Chiare
Il punto della pulizia dei dati è questo: nessuno ne è entusiasta. È la parte del flusso di lavoro sui dati che tutti vorrebbero saltare ma che nessuno può permettersi di ignorare. È la base poco affascinante che rende tutto il resto — le dashboard, le intuizioni, l’intelligenza competitiva — effettivamente affidabile.
Octoparse non rende la pulizia dei dati entusiasmante. Ma la rende veloce, accurata e accessibile a chiunque, indipendentemente dal fatto che abbia mai scritto o meno una riga di codice. E in un mondo in cui le aziende che si muovono più velocemente sui dati vincono, questo è il vantaggio che conta.

Estrai i dati facilmente con funzioni di rilevamento automatico, senza bisogno di competenze di programmazione.
Template di scraping preimpostati per i siti web più popolari per ottenere dati in pochi clic.
Non farti mai bloccare grazie ai proxy IP e all’API avanzata.
Servizio cloud per programmare lo scraping dei dati in qualsiasi momento desideri.
Domande Frequenti sulla Pulizia dei Dati
Cos’è la pulizia dei dati e perché è importante?
La pulizia dei dati è il processo di identificazione e correzione di errori, incongruenze, duplicati e problemi di qualità in un dataset. È importante perché ogni analisi, report o decisione basata su dati “sporchi” è inaffidabile. Per i dati estratti dal web in particolare, la pulizia è essenziale perché i siti web formattano le informazioni in modo incoerente, quindi le esportazioni grezze sono raramente utilizzabili senza essere elaborate.
Quali sono le attività di pulizia dei dati più comuni per i dati estratti?
Le cinque attività più comuni sono: standardizzare i formati di date e numeri tra le fonti, estrarre valori specifici da campi di testo disordinati, rimuovere record duplicati, filtrare le voci spazzatura e tagliare gli spazi o i caratteri indesiderati. Octoparse gestisce queste operazioni attraverso una combinazione di opzioni Clean Data (Replace, Trim spaces, riformattazione di data/ora), il RegEx Tool con generazione di pattern assistita dall’IA, Remove Duplicates in Data Preview, deduplicazione all’esportazione e filtri Trigger configurabili.
Devo conoscere le regex per usare gli strumenti di pulizia dei dati di Octoparse?
No. Il RegEx Tool di Octoparse ha tre schede progettate per diversi livelli di competenza. L’AI RegEx Generator ti permette di incollare fino a 5 stringhe di esempio, evidenziare le parti che vuoi far corrispondere e cliccare su “AI Generate” — scriverà la regex per te. La scheda RegEx Patterns offre una libreria di pattern predefiniti per attività comuni (email, numeri di telefono, URL, date, numeri interi). E il RegEx Builder ti consente di creare pattern utilizzando regole di corrispondenza come “Match by Start”, “Match with End” e “Matched by Content”. Ogni scheda include un RegEx Validator per testare prima dell’applicazione. Gli utenti esperti possono anche scrivere regex personalizzate, ma è del tutto opzionale.
In che modo la pulizia IA di Octoparse è diversa dal semplice utilizzo di ChatGPT o di un altro strumento IA?
Gli strumenti IA generici come ChatGPT possono aiutarti a capire un approccio di pulizia, ma non possono elaborare 50.000 record in blocco, non si integrano direttamente in una pipeline di scraping e non offrono configurazioni di pulizia persistenti e riutilizzabili. Il generatore regex IA di Octoparse è creato appositamente per la pulizia dei dati: gli fornisci esempi dai tuoi dati reali e genera pattern affidabili che vengono eseguiti su larga scala su tutto il tuo dataset, direttamente all’interno del tuo flusso di lavoro di estrazione. Nessun copia-incolla tra vari strumenti.
Posso pulire i dati da più piattaforme nella stessa pipeline?
Assolutamente sì. Gli strumenti di pulizia di Octoparse lavorano sui dati estratti indipendentemente dalla fonte. Se stai estraendo recensioni da Amazon, eBay e Walmart, configuri le tue regole di pulizia una volta sola e si applicano uniformemente a tutti i record. I formati delle date vengono standardizzati, il testo indesiderato viene tagliato, i duplicati vengono intercettati, indipendentemente dalla piattaforma da cui provengono i dati.
La pulizia dei dati è inclusa nel piano gratuito?
Sì. Il piano gratuito ti consente di eseguire fino a 10 task di scraping con accesso completo alle funzionalità di pulizia dei dati, inclusi strumenti regex, conversione dei formati e pulizia assistita dall’IA. Il piano Standard ($69/mese con fatturazione annuale) e il piano Professional ($249/mese con fatturazione annuale) aggiungono esecuzione in cloud, programmazione, maggiore concorrenza e supporto prioritario.
Octoparse può gestire la pulizia di dati non in inglese?
Sì. Gli strumenti di regex e conversione dei formati sono agnostici rispetto alla lingua, e il generatore regex IA funziona con il set di caratteri di qualsiasi lingua. Questo è particolarmente utile per progetti interregionali: ad esempio, pulire le recensioni dei prodotti da Amazon US, Amazon UK e Amazon France in un’unica pipeline. Gli strumenti gestiscono nativamente diverse codifiche dei caratteri.



