Il list crawling è il compito di estrazione dati dal web più comune in assoluto: oltre il 70% dei task di web scraping riguarda liste. I prezzi, il monitoraggio dei concorrenti, la lead generation, seguono tutti schemi ripetibili che possono essere estratti in modo sistematico.
Il modo più rapido per avere successo è identificare i siti “listcrawl-friendly”, applicare un unico set di regole di estrazione a ogni elemento e progettare sin dall’inizio la gestione di paginazione, rate limit e sistemi anti-bot. Questa guida ti mostra esattamente come farlo.
List crawling v.s. web crawling generale
Il list crawling è mirato e strutturato. Invece di visitare ogni pagina, ti concentri su un insieme specifico di pagine che condividono lo stesso layout — ad esempio una categoria prodotti, una job board o un elenco recensioni — ed estrai gli stessi campi da ogni elemento (titolo, prezzo, descrizione, ecc.).
Il web crawling generale, invece, consiste nel visitare il maggior numero possibile di pagine e indicizzarne i contenuti — proprio come fa Google quando scansiona il web per creare i risultati di ricerca. È ampio, superficiale e progettato per scoprire nuove pagine.
Per capirla in modo semplice:
Crawling generale = “Trovami tutto.”
List crawling = “Raccogli questo tipo preciso di dati da ogni elemento negli elenchi.”
Il list crawling richiede anche di gestire paginazione, scroll infinito e pattern ripetuti, mentre il crawling generale si limita a seguire i link senza considerare la struttura dei dati.
Quali tipi di siti sono ideali per il list crawling?
Dopo aver crawlato migliaia di siti, ho notato che alcune caratteristiche predicono con costanza il successo.
TL;DR: dove le liste compaiono più spesso
| Categoria | Esempi | Perché sono utili |
|---|---|---|
| Social Media | Profili Instagram, directory dipendenti LinkedIn, hashtag Twitter | Ricerca competitor, influencer marketing, talent mapping |
| E-commerce | Varianti prodotto Amazon, annunci eBay conclusi | Analisi prezzi, ricerche di mercato |
| Dati Professionali | Round di finanziamento AngelList, repository GitHub | Ricerca investimenti, recruiting |
| Local/Maps | Elenchi su Google Business | Audit SEO locali, monitoraggio dei competitor |
1. E-commerce e Cataloghi Prodotti
Quando visito siti come pagine prodotto di brand o marketplace, cerco:
- Campi dati coerenti tra gli elementi.
- Prezzo, titolo, descrizione e immagini sempre nello stesso punto.
- Paginazione chiara e URL prevedibili, che rendono facile l’estrazione.
Le pagine prodotto di Amazon rappresentano un esempio d’oro del list crawling.
Ogni scheda segue lo stesso template, la paginazione funziona in modo prevedibile e la struttura resta consistente anche quando cambia il design.
2. Directory aziendali e elenchi di attività
Siti come PagineGialle.it, PagineBianche.it o directory settoriali presentano informazioni aziendali in formati standard. Ogni scheda include tipicamente campi coerenti come contatti, orari e recensioni.
Controllo sempre che le schede mantengano gli stessi campi e che categorie e filtri geografici funzionino in modo prevedibile.
3. Siti per l’occupazione
I siti di annunci di lavoro come Indeed usano formati altamente standardizzati. Informazioni come stipendio, località, azienda e data di pubblicazione appaiono in modo coerente.
Ho ottenuto ottimi risultati su Indeed e pagine “Lavora con noi” delle aziende proprio perché gli utenti devono poter confrontare rapidamente posizioni simili — quindi il layout è obbligatoriamente uniforme.
4. Siti di Recensioni e Piattaforme Contenuti
Le piattaforme di recensioni presentano feedback utente in strutture uniformi con sistemi di rating costanti. Aggregatori di notizie come Feedly o Google News usano anteprime standard con metadati (fonte, data, titolo).
Il punto in comune di tutti i siti ideali per il list crawling: stessi campi, stesso layout, variazioni minime.
Come capire se le liste di un sito sono crawlabili
Prima di decidere se un sito è adatto al list crawling, faccio un’analisi di cinque minuti. Questo mi dice se collaborerà o resisterà agli estrattori.
1. Ispeziona il codice sorgente
Per accedere al codice sorgente puoi fare clic con il tasto destro del mouse sulla pagina e seleziona “Visualizza sorgente pagina”. In seguito, cerca gli elementi HTML che contengono i tuoi dati desiderati, nomi di classe coerenti tra elementi simili e markup strutturato come JSON-LD.
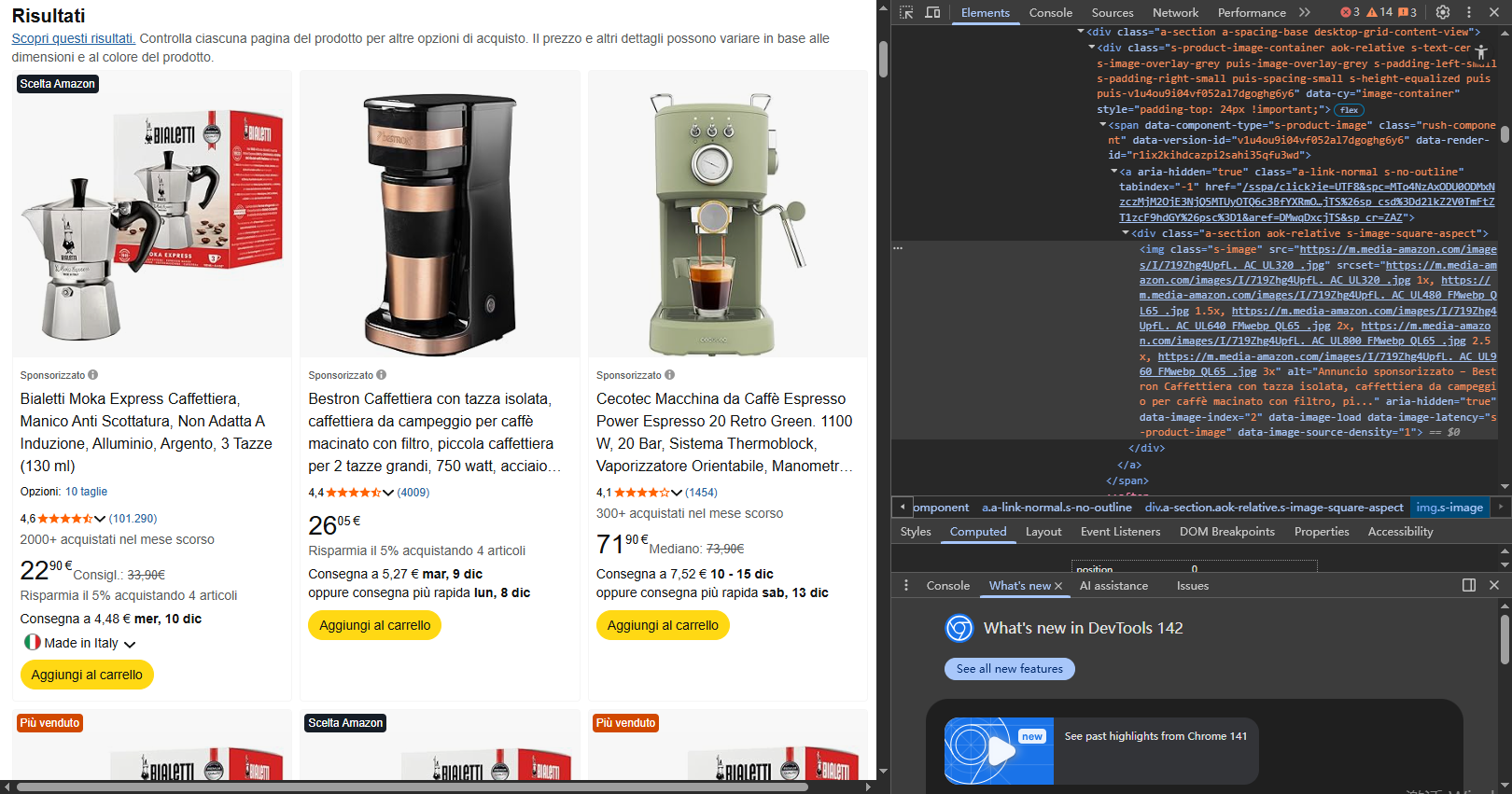
Se vedi i dati nel sorgente HTML, il sito è crawlable.
Nota: Se vedi div vuoti o campi che si popolano via JavaScript, probabilmente il contenuto è dinamico.
2. Controlla la struttura degli URL
I siti crawlabili mostrano URL prevedibili per la navigazione. Ti consiglio di cercare questi pattern nella paginazione. Ad esempio:
- example.com/products?page=1 → page=2
- Oppure pattern per categoria come example.com/elettronica/p2
I segnali d’allarme includono URL che non cambiano o che hanno token complessi generati tramite JavaScript. Una volta, ho trascorso giorni su un sito in cui tutte le pagine condividevano lo stesso URL ma contenuti diversi venivano caricati tramite JavaScript: la paginazione era completamente dinamica.
3. Testa la navigazione manuale
Quello che farei è cliccare manualmente su 3 o 4 pagine.:
- I numeri pagina devono funzionare sempre
- La freccia indietro del browser deve comportarsi bene
- I contenuti della lista devono caricare subito
Se ci sono rotture, la configurazione del crawler (XPath della paginazione, ad esempio) andrà adattata.
4. Controlla il rate limit
Apri 5 o 6 pagine rapidamente nelle nuove schede del navigatore.
Le pagine che non si caricano, che visualizzano domande CAPTCHA o che mostrano messaggi “troppe richieste” indicano che la scansione automatica potrebbe essere troppo aggressiva.
List crawling su diversi tipi di siti web
Se non vuoi scrivere il codice per creare un list crawler, ti consiglio di usare Octoparse, che gestisce tutta la parte tecnica e mi lascia concentrarmi sui dati. È possibile scaricarlo gratuitamente ed è disponibile sia sul Windows che sul Mac.
Diversi tipi di sito organizzano le liste in modi diversi: ecco i 3 più comuni e come li gestisco.
1. Come eseguire il crawling di liste basate su tabelle
Quando hai accesso all’interno di una tabella, incolla nella casella di ricerca sulla schermata principale dell’APP l’url la pagina dalla quale voglio iniziare l’estrazione. Qui faccio crawling su CNN Markets come un esempio.
La pagina viene caricata nel browser integrato. Avvia la funzione di rilevamento automatico: Octoparse scansiona la pagina, individua la tabella e seleziona automaticamente le righe e le colonne.
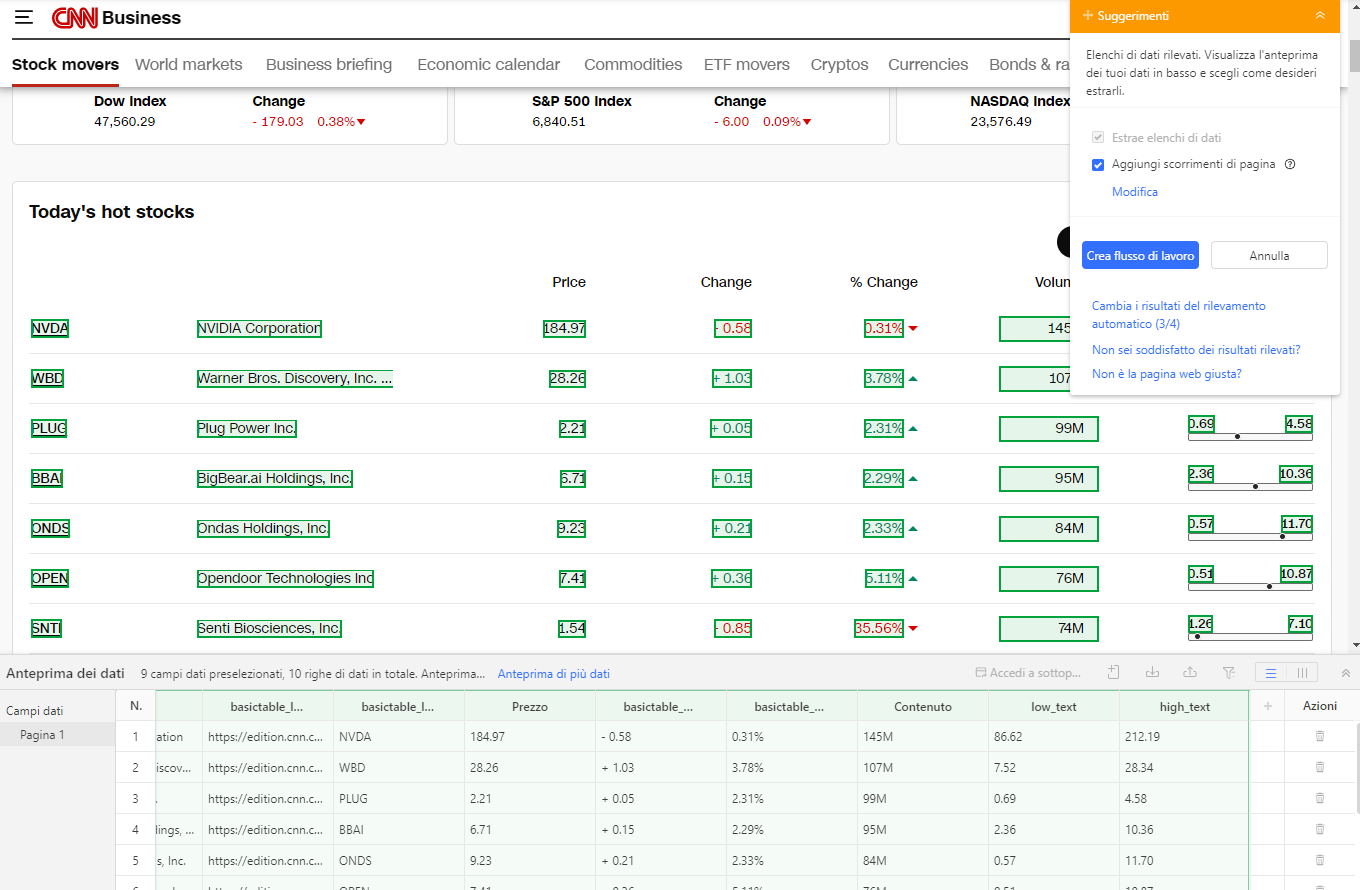
Se qualcosa sfugge all’auto-detect, si può intervenire manualmente:
- seleziona la prima cella della prima riga,
- estendi la selezione fino a includere tutta la riga,
- lascia che Octoparse riconosca in automatico tutte le righe della stessa struttura.
Questa funzione fa risparmiare moltissimo tempo, specialmente quando la tabella contiene decine o centinaia di righe. Se la tabella si estende su più pagine, configura la paginazione indicando a Octoparse come cliccare su “Avanti” o sul numero di pagina successivo.
Arrivando qui puoi procedere con l’esportazione in CSV, Excel o nel formato richiesto dal progetto.
Approfondimento consigliato:
Guida completa per estrarre dati da tabelle con Octoparse.
2. Crawling di dati all’interno di tab o interfacce con schede
Molti siti moderni utilizzano tab, o schede interattive, per suddividere grandi quantità di informazioni nella stessa pagina.
È una struttura molto comune in: pagine prodotto (varianti, specifiche tecniche, recensioni), profili di servizi, portali immobiliari, directory e cataloghi digitali.
In questi casi, estrarre i dati richiede che lo scraper “clicchi” le varie tab per renderne visibile il contenuto.
Ti presento qui il processo in questo caso:
- Carica la pagina in Octoparse.
- Identifica le tab e imposto l’azione di clic sequenziale.
- Aggiungi tempi di attesa per consentire il caricamento dei contenuti (spesso sono in JavaScript o AJAX).
- Utilizza l’auto-detect o la selezione manuale per catturare i dati di ogni tab.
- Imposta un loop quando le tab sono molte o quando sono presenti liste nidificate.
Questo approccio permette di trasformare pagine “chiuse” o difficili da leggere in dataset completi — cosa impossibile con strumenti di scraping più limitati o solo basati su URL statici.
3. Crawling di pagine listing e pagine dettaglio (struttura multipagina)
Questa è senza dubbio la struttura più comune nel web moderno: una pagina elenco (listing) che mostra i prodotti, gli articoli o gli elementi principali, e una pagina dettaglio che contiene informazioni più approfondite.
Per ottenere dataset completi, puoi raccogliere i dati con un approccio a due livelli:
a. Estrazione dalla pagina listing
Inserisci l’URL della pagina delle liste in Octoparse ed esegui il rilevamento automatico per identificare tutti gli elementi presenti. Questo genererà un loop che estrae i dati principali come titolo del prodotto, prezzo o descrizione breve.
b. Estrazione dalla pagina dettaglio
Configura quindi Octoparse per cliccare automaticamente su ogni elemento e aprire la pagina di dettaglio. Qui imposta i campi aggiuntivi per estrarre informazioni più approfondite, come descrizione completa, specifiche tecniche o recensioni.
Imposta anche la paginazione in modo che Octoparse carichi ed estragga i dati da più pagine di risultati. Dopo aver verificato con un test che tutto funzioni correttamente, avvia l’estrazione completa. Con questo metodo puoi ottenere dataset ricchi che combinano informazioni generali e dettagliate in modo efficiente.
Approfondimento consigliato:
Tutorial completo sullo scraping delle pagine dettaglio.
Problemi comuni nel list crawling e come risolverli
Quando si effettua lo scraping di liste di prodotti, articoli o risultati di ricerca, è normale incontrare errori come dati mancanti, paginazione non funzionante, blocchi o CAPTCHA. Di seguito trovi una guida completa ai problemi più frequenti nel list crawling e alle soluzioni pratiche che utilizzo ogni giorno con Octoparse.
1. Nessun dato o dati parziali estratti
Se l’estrattore non recupera dati o ne estrae solo una parte, le cause più comuni sono:
- la pagina non si è caricata completamente
- la selezione degli elementi non è corretta
Come risolvere
- Aumenta il timeout del passaggio Vai alla Pagina Web per permettere il caricamento completo.
- Aggiungi un’azione di scrorrimento per forzare il caricamento dell’intera lista.
- Inserisci brevi tempi di attesa tra i passaggi, soprattutto con contenuti dinamici.
2. Paginazione che salta pagine o perde dati
Una paginazione impostata male può comportare perdita di informazioni o loop infiniti.
Cosa fare
- Controlla che l’XPath del pulsante Avanti sia stabile e univoco.
- Testa manualmente la paginazione dentro Octoparse per verificare che avanzi pagina per pagina.
- Aumenta il timeout di caricamento AJAX per permettere alla nuova pagina di caricarsi.
3. Dati duplicati nell’esportazione
I duplicati sono solitamente causati da una paginazione errata: Octoparse può cliccare la stessa pagina due volte o tornare indietro.
Soluzioni efficaci
- Raffina l’XPath o modifica la modalità di loop.
- Attiva la funzione Rimuovi duplicati durante l’esecuzione in cloud.
- Aggiungi passaggi logici per verificare se la pagina successiva è già stata visitata.
4. Il task si blocca o si congela durante l’esecuzione
Siti molto dinamici o ricchi di JavaScript possono causare blocchi improvvisi.
Come sbloccare il workflow
- Controlla i log di eventi ed errori per capire il punto preciso del blocco.
- Allunga i timeout, inserisci scroll più lenti o intervalli manuali.
- Se il task è molto grande, suddividilo in blocchi più piccoli.
5. CAPTCHA e blocchi anti-bot
I CAPTCHA sono uno dei principali motivi di interruzione dell’estrazione.
Come evitarli
- Usa il risolutore CAPTCHA integrato di Octoparse.
- Attiva la rotazione di proxy e variazione degli header per ridurre il profilo “bot-like”.
- Rallenta la velocità e inserisci ritardi casuali simulando il comportamento umano.
Tabella di sintesi – problemi e soluzioni rapide
| Problema | Causa Probabile | Soluzione Rapida in Octoparse |
|---|---|---|
| Nessun dato o dati parziali | Pagina non caricata del tutto | Scroll + tempi di attesa più lunghi |
| Paginazione che salta pagine | XPath instabile | Auto-paginazione o nuovo XPath |
| Dati duplicati | Loop sulla stessa pagina | “Remove Duplicates” + XPath più stabile |
| Task congelato | Sito pesante in JavaScript | Aumentare timeout e dividere task |
| CAPTCHA | Richieste troppo rapide | Proxy rotation + delay casuali |
Come pulire i dati estratti
Una volta completato il crawling, è fondamentale pulire i dati per analizzarli correttamente. I problemi più comuni includono:
- righe duplicate
- valori mancanti
- formati incoerenti
- testo sporco con HTML o simboli
Ecco cosa faccio per ottenere dataset puliti e pronti all’uso
- Eliminare i duplicati
Le righe duplicate possono confondere l’analisi e portare a conteggi errati. Usa strumenti come “Rimuovi duplicati” di Excel oppure, in Python, il comandodf.drop_duplicates()di Pandas per eliminarle. - Gestire i valori mancanti
Se mancano prezzi o date, prova a riempire i vuoti con valori medi o con dati simili. Se invece i dati mancanti sono troppi, elimina direttamente quelle righe. - Uniformare i formati
Assicurati che tutte le date seguano lo stesso formato e che i prezzi utilizzino uno stile uniforme. Ad esempio, $19.99 e 19.99 USD diventano entrambi 19.99. - Pulire i testi
A volte le descrizioni contengono codice HTML residuo o simboli strani. Rimuovi tag HTML, spazi superflui e qualsiasi elemento indesiderato per mantenere i testi puliti e leggibili.
Strumenti di data cleaning raccomandati
- Excel / Google Sheets: ottimi per dataset piccoli o pulizie rapide
- Python + Pandas: ideale per grandi volumi e pulizia avanzata
- OpenRefine: perfetto per standardizzare e correggere incoerenze senza codice
Ecco un semplice esempio in Python per rimuovere i duplicati e riempire i prezzi mancanti:
Una buona pulizia dei dati mi fa risparmiare tempo in futuro, migliora l’accuratezza delle mie analisi e mi aiuta ad avere fiducia nelle informazioni ricavate dalle mie liste di dati recuperate.
Domande frequenti sul list crawling
- Come gestire infinite scroll e contenuti caricati dinamicamente?
Usa strumenti che eseguono JavaScript (come il browser di Octoparse) e aggiungi scroll o clic sui tab con tempi di attesa adatti.
- Come evitare blocchi?
Proxy rotation, user-agent rotation, ritardi casuali e rispetto dei limiti di richiesta.
- Posso estrarre dati dietro login?
Sì, seguendo un workflow di login automatico in Octoparse e gestendo i cookie correttamente.
- Ci sono rischi legali?
Lo scraping di pagine pubbliche è generalmente consentito, ma alcuni siti vietano l’automazione: è sempre meglio controllare i Termini di Servizio.
Conclusione
Il list crawling è uno dei pilastri fondamentali del web scraping. Capire come gestire paginazione, caricamenti dinamici, CAPTCHA e problemi comuni permette di ottenere dati completi, puliti e affidabili, indispensabili per analisi di mercato, pricing e business intelligence.
Con strumenti come Octoparse, anche senza programmare è possibile costruire flussi di lavoro stabili e scalabili, ridurre errori e ottenere dataset pronti all’uso.



