Voglio essere onesto: la maggior parte dei tutorial su come fare web scraping ti mente se non ti spiega cos’è un headless browser.
Ti mostrano:
- requests.get()
- BeautifulSoup
- Finito.
Ma prova ad applicarlo su qualsiasi sito web moderno e reale, e ti ritroverai con contenuti vuoti, pagine interrotte e dati mancanti.
Questo perché i siti moderni non forniscono più i dati direttamente. Si aspettano un browser reale, e se non ne stai eseguendo uno, hai già perso in partenza.
È esattamente qui che entrano in gioco gli headless browser.
Sono essenzialmente versioni di Chrome o Firefox eseguite in modo invisibile, che eseguono JavaScript, cliccano su pulsanti, caricano contenuti dinamici e si comportano come un utente reale.
E una volta che inizi a usarli, smetti di scontrarti con i siti web moderni e inizi a fare scraping e ad automatizzarli nel modo in cui sono stati effettivamente progettati per essere utilizzati.
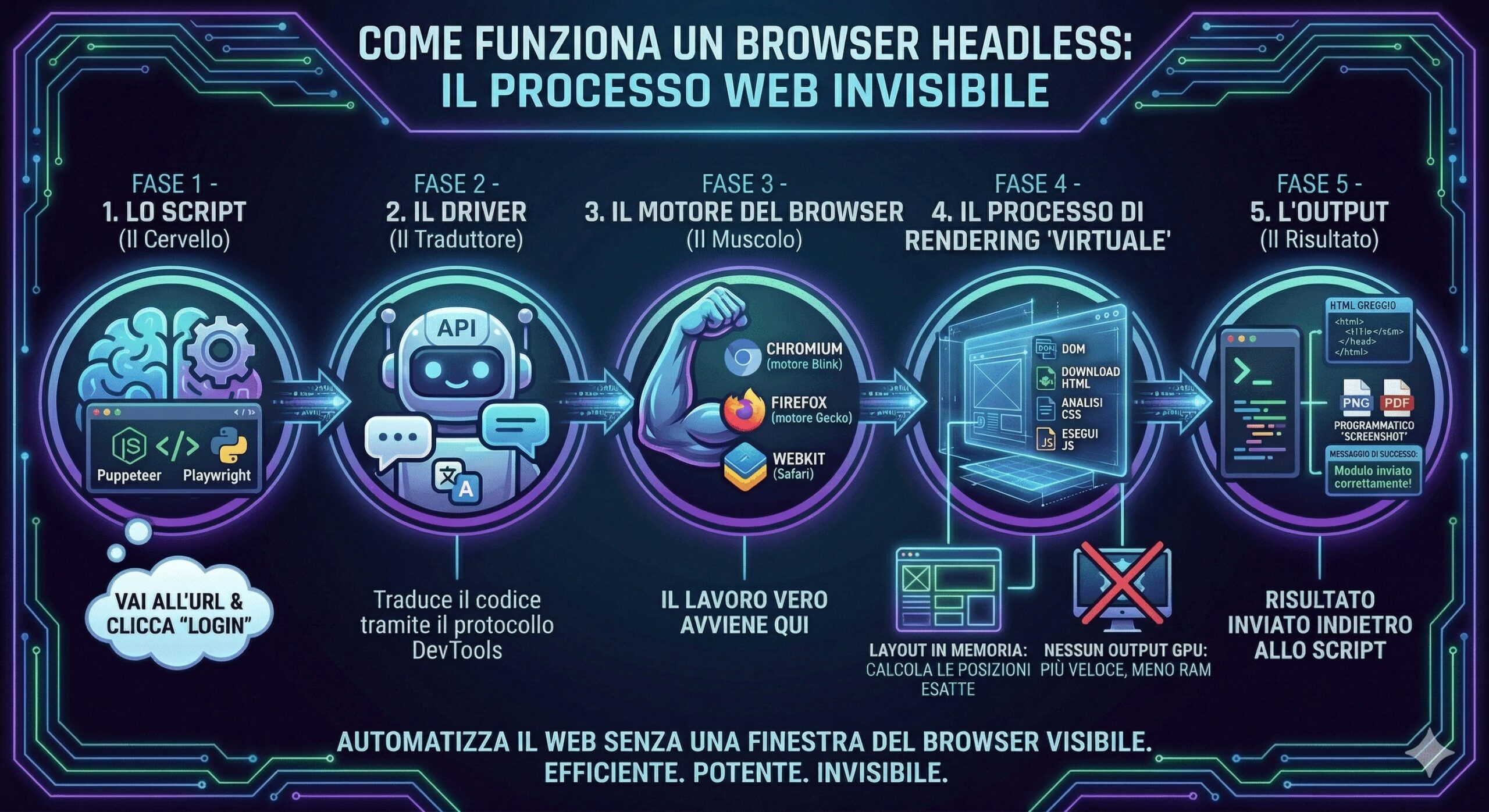
Cos’è un browser headless?
Un headless browser è semplicemente un browser reale eseguito senza una finestra o uno schermo visibile.
Questa idea di “eseguire Chrome senza l’interfaccia di Chrome” è esattamente il modo in cui il team di Chromium stesso descrive la modalità headless, in cui l’intero motore del browser viene eseguito in un ambiente non presidiato senza alcuna interfaccia utente visibile.
Vuoi un esempio pratico? Pensa a Chrome o Firefox.
Ora rimuovi la finestra, le schede, i pulsanti e tutti gli elementi visivi.
Quello che resta è solo il motore, e quel motore è ciò che chiamiamo un headless browser.
La parte migliore è che questo motore continua a:
- caricare le pagine e renderizzare il DOM
- eseguire JavaScript e chiamate AJAX
- gestire i cookie
- effettuare login e cliccare sui pulsanti
Ma invece di essere tu a cliccare, è il tuo codice a farlo. Tutto qui.
Ed è questo che ti dà un vantaggio sleale nel web scraping, nell’automazione, nei test QA e molto altro.
Per renderlo ancora più chiaro, pensala in questo modo:
- Browser normale: apri Chrome, clicchi, scorri, digiti e i dati si caricano
- Headless browser: il tuo script clicca, scorre, digita e i dati si caricano
Ora sai cos’è un headless browser, quindi vediamo come funziona effettivamente.
Perché cURL e richieste falliscono sui siti moderni
Ora, lascia che ti mostri il problema prima di approfondire gli Headless Browser.
Supponiamo che tu provi questo:
E quello che ti aspetti sono dati in formato JSON o HTML.
Invece, ottieni:
Ma perché? Perché la pagina si carica in questo modo:
- Passaggio 1: il server invia un guscio vuoto
- Passaggio 2: JavaScript viene eseguito
- Passaggio 3: JS interroga l’API
- Passaggio 4: JS renderizza i prodotti
Ma cURL non esegue mai il passaggio 2. Quindi non vede mai il passaggio 3 o 4.
Ecco perché le richieste falliscono, i parser HTML falliscono e di conseguenza lo scraping fallisce.
Non perché stai sbagliando qualcosa, ma perché non stai operando all’interno di un browser.
E gli Headless browser risolvono esattamente questo problema. Per essere più chiari, ecco i passaggi su cui si concentrano i browser headless:
- aprire la pagina
- eseguire JavaScript
- attendere che tutto si carichi
- quindi estrarre i dati
Sì, esattamente come un browser umano, ed è questo che aiuta nel web scraping, nell’automazione, nei test QA e altro ancora.
Scegliere un headless browser e avviare il primo script di automazione
Ora sai cos’è un headless browser e il problema che risolve.
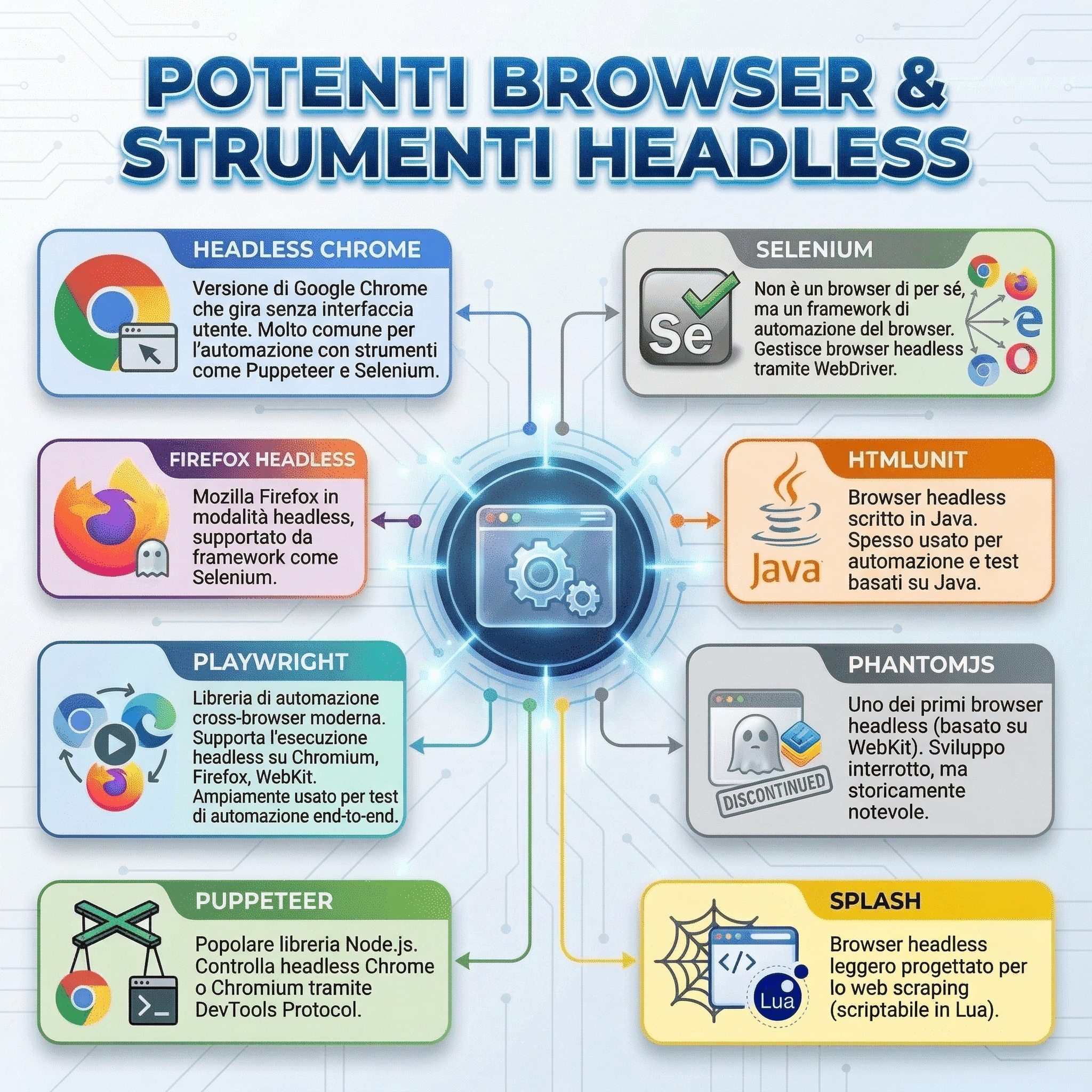
E grazie a questo, abbiamo a disposizione diversi strumenti per browser headless, ma alcuni sono particolarmente popolari.
Tra tutti, questi sono i più comuni e ampiamente utilizzati:
Diversi benchmark indipendenti e guide agli strumenti dimostrano che Playwright e Puppeteer superano generalmente Selenium in termini di velocità di esecuzione, perché comunicano direttamente con il browser tramite il protocollo DevTools, mentre il livello WebDriver di Selenium aggiunge un sovraccarico extra.
Ora, proviamo Playwright ed eseguiamo il nostro primo script per headless browser.
Prima installa:
npm install playwright
E poi esegui il codice seguente:
Nitin, cosa è appena successo?
Bene, il tuo script ha avviato Chrome, ha aperto la pagina, ha atteso che venisse renderizzata, ha estratto i dati e poi ha chiuso il browser.
Ha fatto esattamente quello che faresti tu manualmente, ma in modo automatizzato.
Se vuoi provarlo tu stesso, esegui il codice qui sotto:
Ma ecco il problema di cui nessuno parla
Ed ecco la parte che la maggior parte dei tutorial salta comodamente, perché la maggior parte di essi non costruisce e utilizza effettivamente gli headless browser in scenari del mondo reale.
Senza dubbio, gli headless browser sono incredibilmente potenti.
- Possono renderizzare app pesanti basate su JavaScript.
- Si comportano come utenti reali.
- Funzionano magnificamente in configurazioni serverless.
- Scalano con i proxy e ti permettono di automatizzare e velocizzare il web scraping.
Ma nella vita reale, diventano lentamente noiosi e complicati.
Perché usare un headless browser non è mai solo “usa un headless browser → estrai i dati → finito”.
Inizia in modo semplice, ma poi ci si scontra con la realtà.
- Per prima cosa, aggiungi dei tentativi (retries) perché le richieste falliscono casualmente.
- Poi i proxy, perché vieni bloccato.
- Poi la gestione dei CAPTCHA perché spunta Cloudflare.
- Poi la logica di paginazione, le sessioni di login, i limiti di frequenza (rate limiting).
- Infine logging, pianificazione ed esportazioni.
E prima che tu te ne accorga, il tuo simpatico script di 30 righe diventa 800 righe di codice.
A questo punto, non stai più “facendo scraping di un sito web”. Stai praticamente costruendo un mini framework di scraping.
Come vedi, finisci per passare più tempo a costruire e mantenere lo scraper che a estrarre effettivamente i dati.
Questo è il costo nascosto che nessuno ti dice sugli headless browser.
Ed è esattamente qui che strumenti come Octoparse iniziano ad avere molto più senso.
Octoparse: un’alternativa più semplice agli headless browser
Nitin, cos’è Octoparse? Beh, è una soluzione no-code per il web scraping, e per te può agire come molto più di un semplice headless browser grezzo.
Ma come? Prima di tutto, gestisce le cose a cui non vuoi pensare:
- gestione di più istanze del browser
- accodamento, riavvio delle esecuzioni fallite, la gestione dei proxy e dei limiti di frequenza
- la risoluzione dei CAPTCHA e altre mitigazioni anti-bot
- regolazione delle impronte digitali (fingerprint) del browser e dei modelli di richiesta per far sembrare lo scraping umano ed evitare il rilevamento
- pianificazione, esecuzione in cloud ed esportazione dei dati senza scrivere codice
E la parte migliore? Decide come eseguire il tuo compito in base al sito:
- utilizza un motore leggero per pagine semplici
- passa alla modalità headless completa (o persino a browser visibili) quando necessario
- sceglie automaticamente l’approccio più stabile ed efficiente in termini di costi
Come vedi, non è solo un livello visivo sopra gli headless browser, ma gestisce e controlla effettivamente come vengono eseguiti.
Ed è esattamente ciò che rende il processo facile da capire e da seguire.
Per iniziare, visita semplicemente il sito ufficiale di Octoparse, clicca sul pulsante “Start a free trial” per creare il tuo account, e poi scarica la loro applicazione.
Successivamente, puoi creare un’attività personalizzata o utilizzare uno dei loro modelli pronti all’uso per estrarre dati con le caratteristiche e le funzionalità di cui hai bisogno.
Quindi, se il tuo obiettivo è:
- fare scraping annunci immobiliari o estrarre 1.000 pagine
- eseguirlo quotidianamente
- esportare in CSV
- ed evitare logiche complesse
Allora Octoparse di solito è tutto ciò di cui hai bisogno, e il tuo lavoro viene svolto senza mal di testa. Per la maggior parte dei casi d’uso aziendali, è più che sufficiente.
Quando usare un headless browser (e quando evitarlo)
Ora sai cos’è un headless browser, perché esiste e come iniziare, ma la maggior parte dei principianti lo usa ancora in modo improprio.
Usano gli headless browser ovunque, quando in realtà dovresti usarli solo quando sono effettivamente necessari.
Per essere più precisi, usa un headless browser quando:
- il sito fa un uso massiccio di JavaScript
- è richiesto il login o devono essere inviati dei moduli
- c’è uno scorrimento infinito (infinite scroll)
- sono necessari clic sui pulsanti per caricare i dati
- hai a che fare con dashboard dinamiche
- il sito ha protezioni anti-bot
- hai bisogno di acquisire screenshot o usare funzioni come puppeteer salvare pagina in pdf
Ma Nitin, quando non dovresti usarlo? Non usare un headless browser quando il sito fornisce pagine HTML statiche, un’API semplice ti dà già i dati, o hai bisogno di uno scraping massivo e veloce con un sovraccarico minimo.
Ma quando dovresti usare cURL, un headless browser e Octoparse? Bene, ecco il semplice modello mentale che uso io:
- Usa cURL o semplici client HTTP quando c’è un’API pulita o HTML statico. È il metodo più veloce e con meno sovraccarico.
- Usa Playwright o Puppeteer quando hai bisogno del controllo totale. Flussi complessi, logica personalizzata, integrazioni profonde o qualsiasi situazione in cui desideri controllare ogni singolo passaggio.
- Usa Octoparse quando il vero problema non è “come fare scraping”, ma “come eseguire questa operazione in modo affidabile ogni giorno su larga scala”. Sai che può gestire l’orchestrazione del browser, l’infrastruttura e i dettagli anti-bot, utilizzando un mix di WebView, modalità headless e visibile a seconda delle necessità.
Domande frequenti sugli headless browser
1. Gli headless browser sono più lenti delle normali librerie di scraping?
Sì, perché un headless browser avvia letteralmente Chrome (chrome headless browser) o Firefox dietro le quinte.
Questo significa un maggiore utilizzo della memoria, un maggiore consumo di CPU, tempi di avvio più lenti e meno processi simultanei.
Quindi, rispetto a librerie semplici come requests o all’accesso diretto alle API, gli headless browser sono sempre più lenti.
2. Quale dovrei scegliere tra Playwright, Puppeteer e Selenium?
Se stai iniziando oggi, usa semplicemente Playwright. È più veloce, più moderno e supporta più browser nativamente.
Anche Puppeteer è ottimo, ma è principalmente focalizzato su Chrome. Selenium è altrettanto potente, ma risulta più pesante e datato a meno che tu non ne abbia specificamente bisogno per test aziendali.
3. Gli headless browser possono essere bloccati o rilevati?
Assolutamente sì. I siti web possono ancora rilevare gli headless browser attraverso segnali come troppe richieste, comportamenti innaturali, assenza di ritardi, indirizzi IP ripetuti o intestazioni (headers) incomplete.
4. Quando dovrei evitare di usare gli headless browser e usare invece qualcosa come Octoparse?
Se il tuo obiettivo è estrarre migliaia di pagine, eseguire lavori giornalieri, esportare dati in CSV o Excel e non hai bisogno di logiche di ingegnerizzazione personalizzate, allora Octoparse è la scelta migliore.
Usare Playwright o Puppeteer in questo caso ti farà solo perdere tempo, e probabilmente passerai settimane a fare il debug di qualcosa che uno strumento visivo può risolvere in 20 minuti.



