Come principiante, ho costruito un web crawler ed estratto con successo 20k dati dal sito web di Amazon Career. Vuoi sapere come creare un web crawler e creare un database che alla fine diventa il tuo asset a costo zero? Questo articolo condividerà con te i diversi modi di raggiungerlo passo dopo passo, inclusi i modi utilizzando codifica e quelli senza codice.
Cos’è un Web Crawler
Un web crawler è un bot internet che indicizza il contenuto dei siti web (leggi la definizione dettagliata su Wikipedia). Ha la capacità di estrarre automaticamente le informazioni e i dati target dai siti web ed esportare i dati in formati strutturati (elenco/tabella/database). Ecco un video che spiega il web crawler e la differenza tra web crawler e web scraper.
Potresti chiederti se il web crawler è legale o meno, beh, dipende. Ma in generale, è totalmente legale nella maggior parte dei paesi raccogliere dati pubblici su un sito web.
Perché si ha bisogno di un web crawler
Immagina un mondo senza Google Search. Quanto tempo che ci vorrà per ottenere una ricetta per nuggets di pollo da Internet? Ogni giorno vengono creati 2,5 quintilioni di byte di dati online. Senza motori di ricerca come Google, sarà come cercare un ago in un pagliaio.
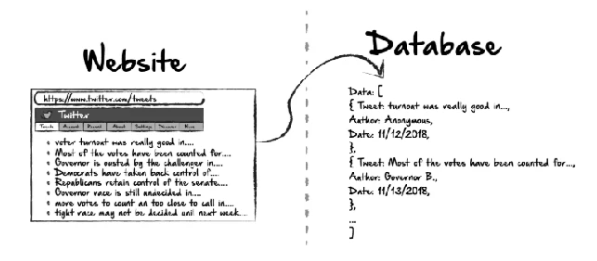
Un motore di ricerca è un tipo unico di web crawler che indicizza i siti web e trova pagine web per noi. Oltre ai motori di ricerca, è possibile anche costruire un web crawler personalizzato per aiutarti a raggiungere:
1. Aggregazione di contenuti: funziona per compilare informazioni su argomenti di nicchia da varie risorse in una singola piattaforma. Di conseguenza, è necessario eseguire il crawling dei siti web famosi per alimentare la tua piattaforma in tempo.
2. Analisi del sentiment: è anche chiamata estrazione delle opinioni. Come suggerisce il nome, è il processo di analisi delle opinioni pubbliche su un prodotto o servizio. Richiede un insieme monotono di dati per valutare con precisione. Un web crawler può estrarre post di X, recensioni e commenti per l’analisi.
3. Lead generation: ogni azienda ha bisogno di lead di vendita. Ecco come sopravvivono e prosperano. Diciamo che prevedi di realizzare una campagna di marketing che si rivolga a un settore specifico. È possibile estrarre email, numeri di telefono e profili pubblici da un elenco di espositori o partecipanti a fiere, come i partecipanti al Wine2Wine Business Forum 2023.
Come costruire un web crawler con script di codice
La scrittura di script con linguaggi informatici è utilizzata prevalentemente dai programmatori. Può essere potente quanto lo crei tu. Ecco un esempio di un frammento di codice bot.
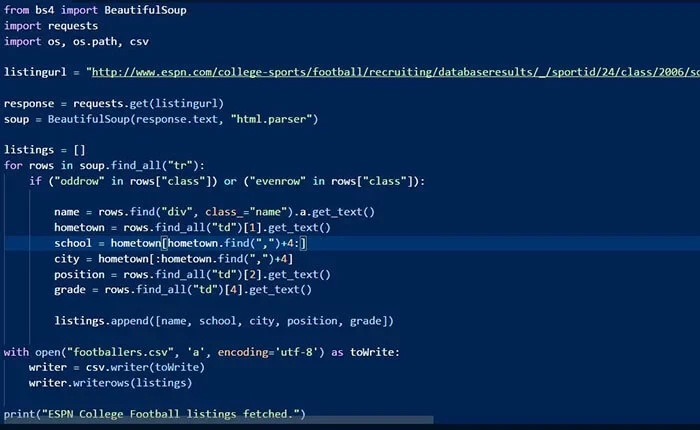
3 passaggi per creare un web crawler usando Python
Passaggio 1: Inviare una richiesta HTTP all’URL della pagina web. Risponde alla tua richiesta restituendo il contenuto delle pagine web.
Passaggio 2: Analizzare la pagina web. Un analizzatore creerà una struttura ad albero dell’HTML poiché le pagine web sono intrecciate e annidate insieme. Una struttura ad albero aiuterà il bot a seguire i percorsi che abbiamo creato e a navigare per ottenere le informazioni.
Passaggio 3: Utilizzare la libreria Python per cercare nell’albero di analisi.
Tra i linguaggi di programmazione per un web crawler, Python è facile da implementare rispetto a PHP e Java. Tuttavia ha una curva di apprendimento ripida che impedisce a molti professionisti non tecnici di utilizzarlo. Anche se è una soluzione economica scrivere la tua, non è ancora sostenibile rispetto al ciclo di apprendimento prolungato entro un lasso di tempo limitato.
Strumento di web crawling senza codice gratuito
Se non vuoi imparare a programmare, puoi provare a utilizzare strumenti di web scraping sul mercato. Qui raccomandiamo Octoparse, che è un creatore di web crawler gratuito e non richiede codifica. Scarica e installa sul tuo dispositivo Windows/Mac, e segui i semplici passaggi qui sotto.
3 passaggi per costruire un web crawler senza programmazione
Passaggio 1: Scaricare Octoparse e copia un link della pagina web
Scarica e installa Octoparse sul tuo dispositivo e incolla l’URL della pagina web target nello schermo principale. Inizierà automaticamente a rilevare per costruire un flusso di lavoro del crawler. Si può anche selezionare Custom task per provare più opzioni personalizzate.
Passaggio 2: Personalizzare i campi dati del web crawler
Si possono semplicemente visualizzare in anteprima i dati rilevati e fare clic sul tasto Create workflow per costruire il crawler. È possibile personalizzare il campo dei dati come ti serve facendo clic sulla posizione dei dati target con i suggerimenti. Octoparse supporta l’impostazione della paginazione facendo clic sul pulsante di Pagina successiva in modo che il crawler possa effettuare l’impaginazione.
Passaggio 3: Eseguire il web crawler per estrarre i dati ed esportarli in file Excel
Una volta che hai finito di impostare i campi di estrazione, fai clic sul pulsante Run per eseguire il crawler. Si può scaricare i dati su dispositivi locali tramite Excel o CSV.
Se hai ulteriori domande, vai alla guida utente per saperne di più. Octoparse fornisce anche modelli di attività che coprono oltre 30 siti web per aiutare i principianti a sentirsi a proprio agio all’inizio. Questi modelli consentono agli utenti di catturare i dati senza configurazione del task e sono estremamente adatti ai principianti.
Conclusione
Scrivere script può essere doloroso in quanto ha costi iniziali e di manutenzione elevati. Nessuna pagina web è identica e dobbiamo scrivere uno script per ogni singolo sito. Non è sostenibile se devi eseguire il crawl di molti siti web diversi. Inoltre, i siti web tendono a cambiare layout e strutture dopo un periodo di tempo. Di conseguenza, dobbiamo correggere gli errori e regolare il crawler di conseguenza. Uno strumento di web crawler come Octoparse è più pratico per l’estrazione di dati a livello aziendale con meno sforzo e costi minori.