Hai mai pensato che Google Sheets possa fare il web scraping per te? Infatti, essendo un potente strumento basato sul cloud, Google Sheets può raccogliere dati dai siti web utilizzando 5 funzioni! Con i dati estratti, puoi condividerli direttamente con il tuo team o con gli amici, oppure integrarli con altri strumenti di terze parti.
Leggendo le parti seguenti, potrai imparare i passaggi dettagliati su come sfruttare queste 5 funzioni, oltre a un altro strumento di scraping automatizzato che rende l’intera attività ancora più facile.
5 Funzioni di Fogli Google per il Web Scraping
Metodo 1: Utilizzo di ImportXML in Fogli Google
ImportXML è una funzione di Google Spreadsheets che consente di importare dati da fonti strutturate come XML, HTML, CSV, TSV e feed RSS utilizzando query XPath.
Ecco come appare:
=IMPORTXML(URL, xpath_query, locale)
- URL: L’URL della pagina web.
- xpath_query: Una query XPath per selezionare i dati desiderati.
- locale: Un codice di lingua e regione da utilizzare durante l’analisi dei dati. Se non specificato, viene utilizzato il locale del documento.
Di seguito, ti mostrerò un esempio di come estrarre i titoli degli ultimi articoli dal Blog di Octoparse.
Per fare ciò, prima devi creare un nuovo foglio di calcolo o aprirne uno esistente. Quindi clicca sulla cella dove vuoi che appaiano i dati importati e inserisci l’URL e l’XPath dell’elemento che vuoi estrarre.
Devi ottenere l’Xpath dei titoli degli articoli ispezionando (clic destro e selezionando “Ispeziona”) l’elemento target nel sito web.
Ecco,
- URL: https://www.octoparse.com/blog
- XPath Query: //h2
//h2 significa l’XPath esatto di tutti i titoli dei blog nella prima pagina del blog di Octoparse.
Quindi, la funzione completa sarebbe:
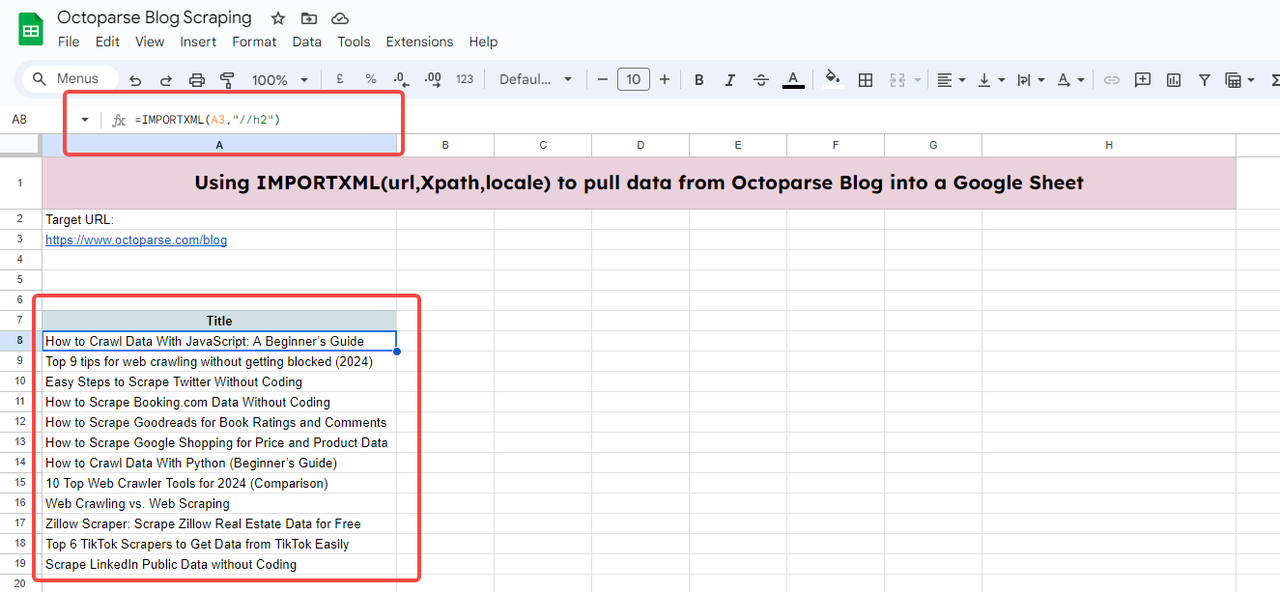
=IMPORTXML(“https://www.octoparse.com/blog”, “//h2”)
Inserisci la funzione nella cella dove vuoi che appaiano i dati importati. Potrebbe essere necessario anche cliccare su “accedi ai dati” per permettere a Google Sheets di importare dati dall’esterno.
Dopo qualche secondo di caricamento, otterrai tutti i titoli della prima pagina del blog.
Suggerimenti:
- Puoi anche sostituire l’URL con una cella purché inserisca l’URL nella cella. Qui, vedi A3.
- Ricorda di aggiungere le virgolette quando inserisci l’XPath e l’URL. Se li sostituisci con il contenuto della cella, allora non sono necessarie virgolette.
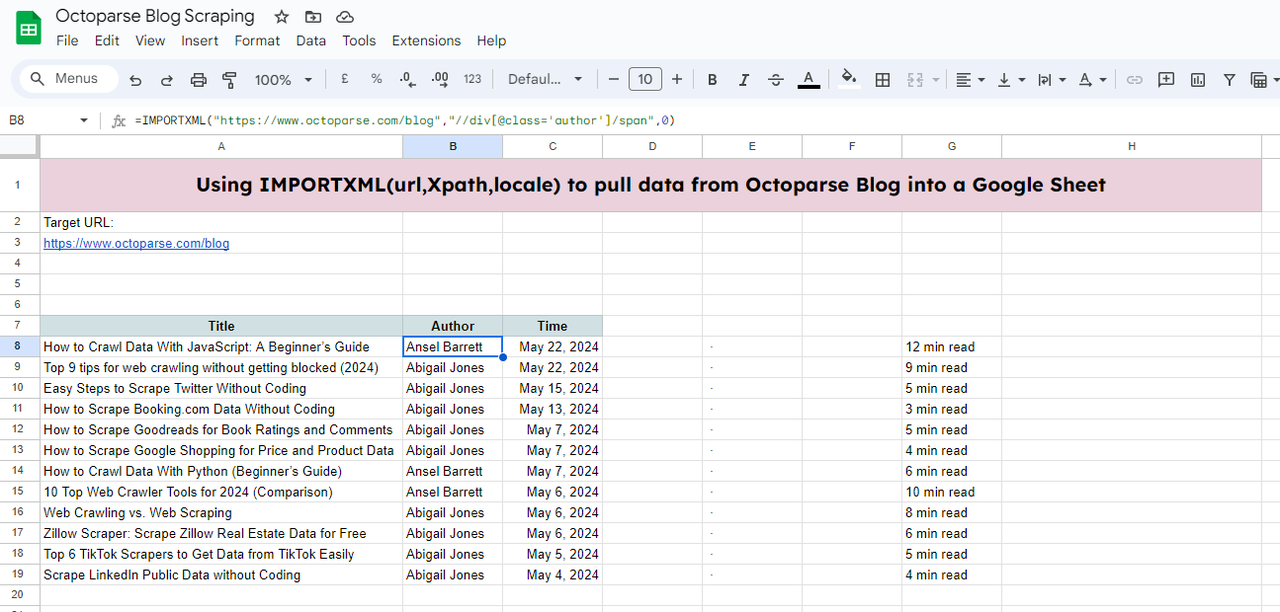
- Se ci sono già virgolette, le virgolette all’interno dell’XPath devono essere singole. Ad esempio, “//div[@class=’author’]/span”. L’ortografia errata come “//div[@class=”author”]/span” porta a un errore.
- Puoi ignorare il “Locale” se desideri il locale del documento.
- Se non sei familiare con XPath, trova la cheat sheet di XPath.
Puoi continuare a riempire il foglio con altri dati seguendo gli stessi passaggi sopra.
Google sheet di esempio: https://docs.google.com/spreadsheets/d/18Tkp6rP9p1Az_AlXyOJlrqVxwESpTDOf7MSIweZnOD0/edit#gid=0
Metodo 2: Utilizzo di ImportHTML in Fogli Google
La funzione IMPORTHTML in Google Sheets è progettata per recuperare dati da tabelle e liste all’interno di pagine HTML. Per usarla, avrai bisogno dell’URL del sito target e della query, che può essere “table” o “list”.
La funzione sarà simile a questa:
=IMPORTHTML(url, query, index)
- url: L’URL della pagina web contenente i dati.
- query: “table” o “list”, a seconda di ciò che desideri estrarre.
- index: La posizione della tabella o della lista sulla pagina web (a partire da 1).
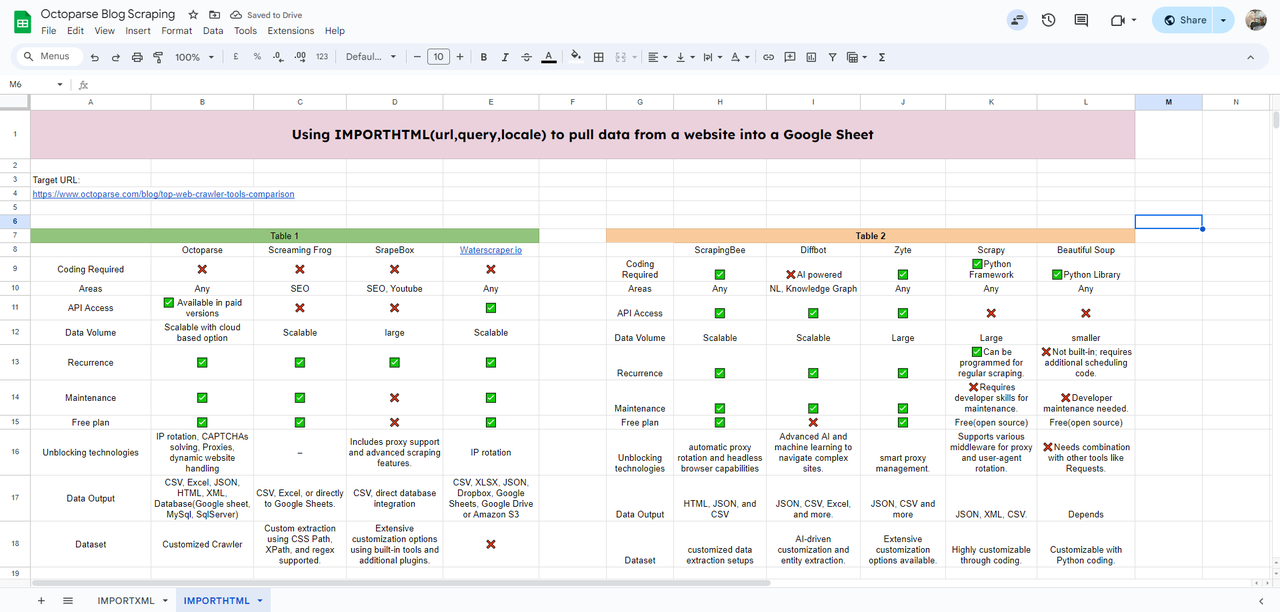
In questo esempio, estrarrò una tabella da uno dei blog di Octoparse.
Per iniziare, prima crea un nuovo foglio e poi apri l’URL target.
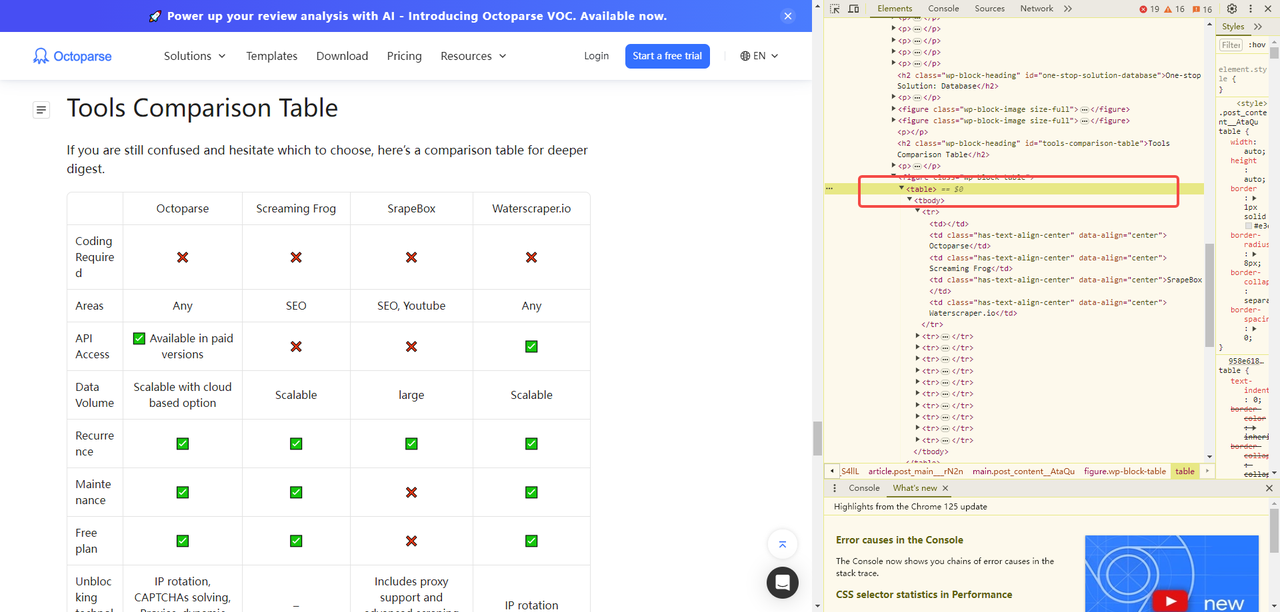
Qui puoi vedere l’HTML della nostra tabella target etichettato <table>; se vuoi estrarre una lista, allora l’etichetta sarebbe <list>.
Per estrarre la tabella dal blog, dobbiamo inserire la funzione IMPORTHTML nella cella dove vogliamo che appaiano i dati importati.
Inserisci:
=IMPORTHTML(“https://www.octoparse.com/blog/top-web-crawler-tools-comparison”, “table”, 1)
Quindi, avrai la tabella caricata.
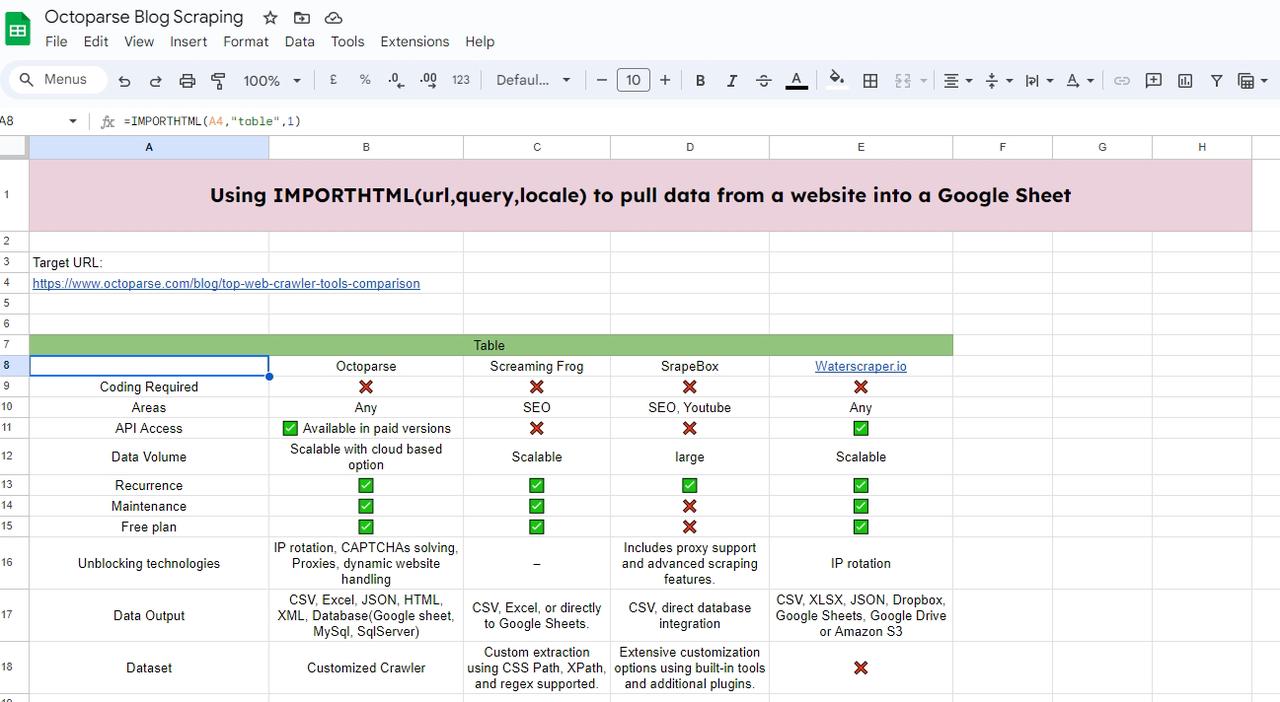
Puoi continuare a estrarre cambiando l’indice della tabella a 2, così otterrai la seconda tabella nel blog.
Suggerimenti:
- Dovrai aggiungere le virgolette doppie alla query.
- Puoi sostituire l’URL con una cella dove l’URL è popolato.
Metodo 3: Utilizzo di ImportDATA in Fogli Google
La funzione IMPORTDATA importa dati da un dato URL in formato CSV (Comma-Separated Values) o TSV (Tab-Separated Values) direttamente in Google Sheets.
Tutto ciò che ti serve è solo un URL del tuo sito target. Semplice, vero?
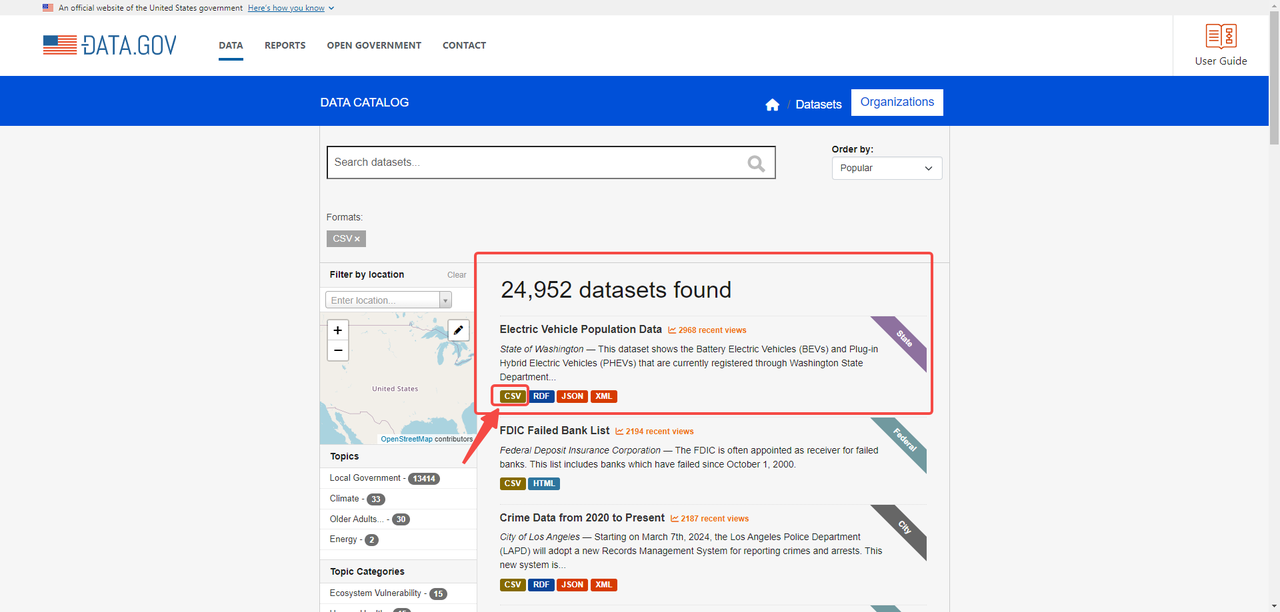
Diciamo che dobbiamo estrarre dati dal sito web: https://catalog.data.gov/dataset/?res_format=CSV
Sul sito, possiamo vedere il file CSV tramite il link: https://data.wa.gov/api/views/f6w7-q2d2/rows.csv?accessType=DOWNLOAD (passa il mouse sul pulsante CSV e fai clic destro per copiare l’indirizzo)
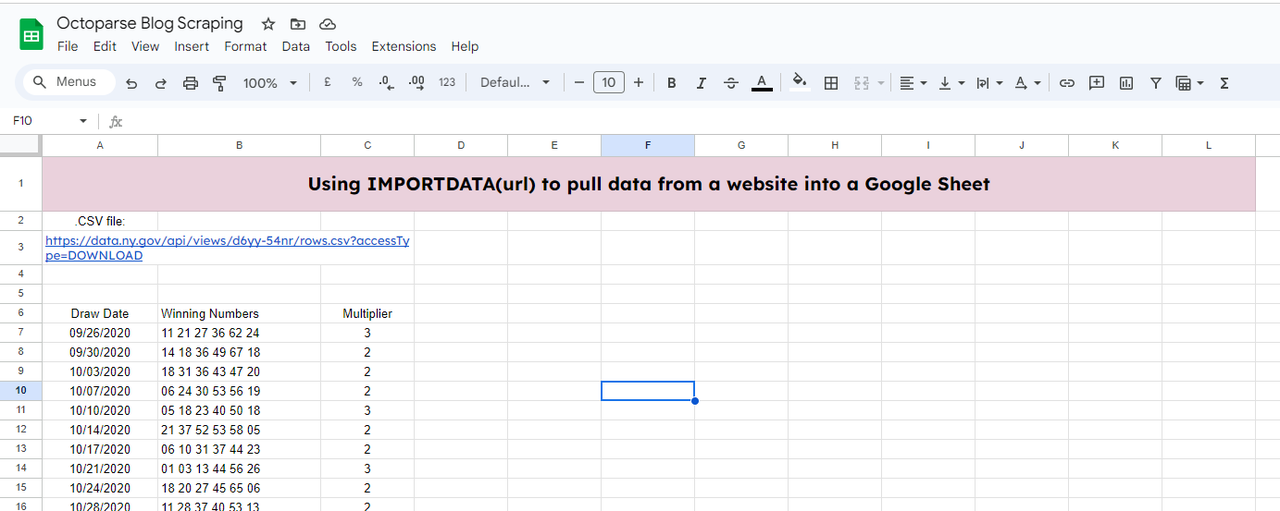
Per importare i dati nel tuo Google Sheets, prima dovrai creare un nuovo foglio come abbiamo fatto nei due metodi precedenti. E utilizza la funzione seguente:
=IMPORTDATA(A3,”,”)
A3: è dove si trova il link del file .csv
“,”: separa i campi dati nel file importato
Quindi, otterrai i dati importati.
Metodo 4: Utilizzo di ImportFeed in Fogli Google
La funzione IMPORTFEED recupera i dati del feed RSS o ATOM da un dato URL.
Sembra così:
=IMPORTFEED(url, [query], [headers], [num_items])
- url: L’URL del feed RSS o ATOM.
- query: [Opzionale] Una query per recuperare elementi specifici. Il valore predefinito è “” (stringa vuota), che recupera tutti gli elementi.
- headers: [Opzionale] Se includere le intestazioni. Il valore predefinito è TRUE.
- num_items: [Opzionale] Il numero di elementi da recuperare. Il valore predefinito è 20.
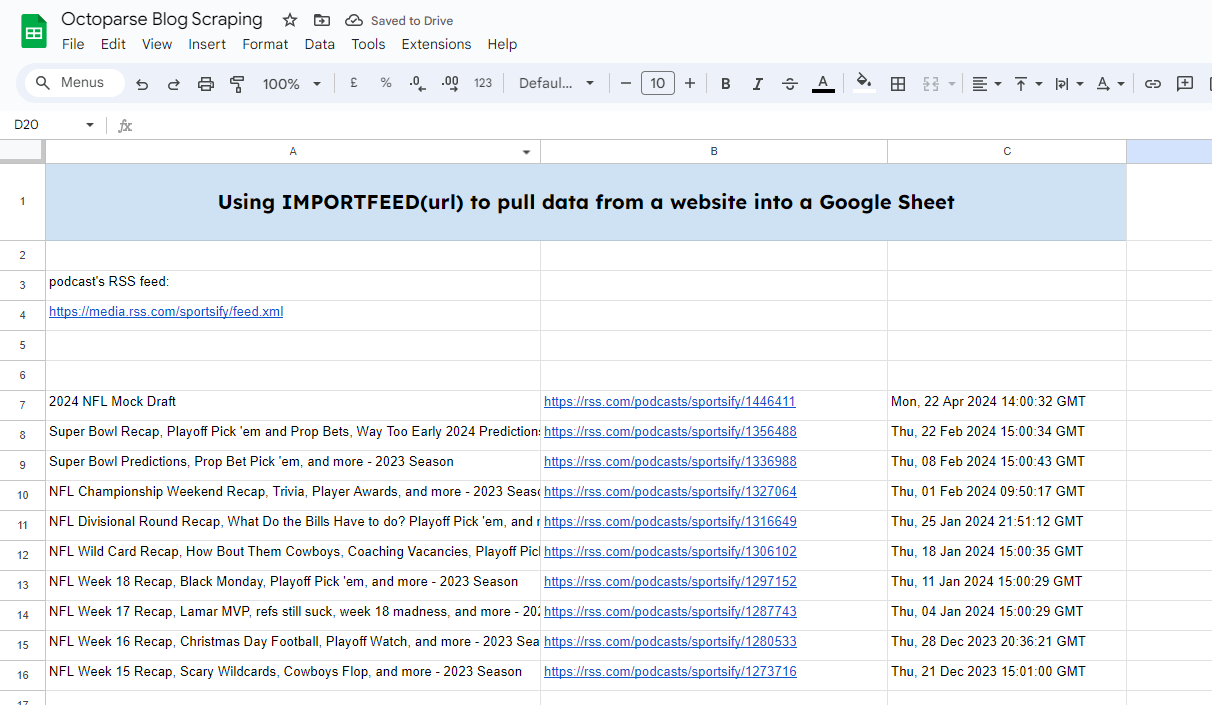
Per fare ciò, avremo bisogno del feed RSS di un podcast: https://rss.com/podcasts/sportsify/
Quindi, inserisci la funzione:
=IMPORTFEED(A4,””,””,10)
Qui ho inserito il link del feed RSS in A4. E voglio estrarre 10 feed.
E otterrai il risultato molto rapidamente.
Metodo 5: Utilizzo di ImportRange in Fogli Google
La funzione IMPORTRANGE in Google Sheets consente di importare dati da un foglio di calcolo Google Sheets a un altro. Questo è particolarmente utile per consolidare dati da più fonti o condividere dati tra diversi fogli mantenendoli collegati dinamicamente.
Ecco come appare:
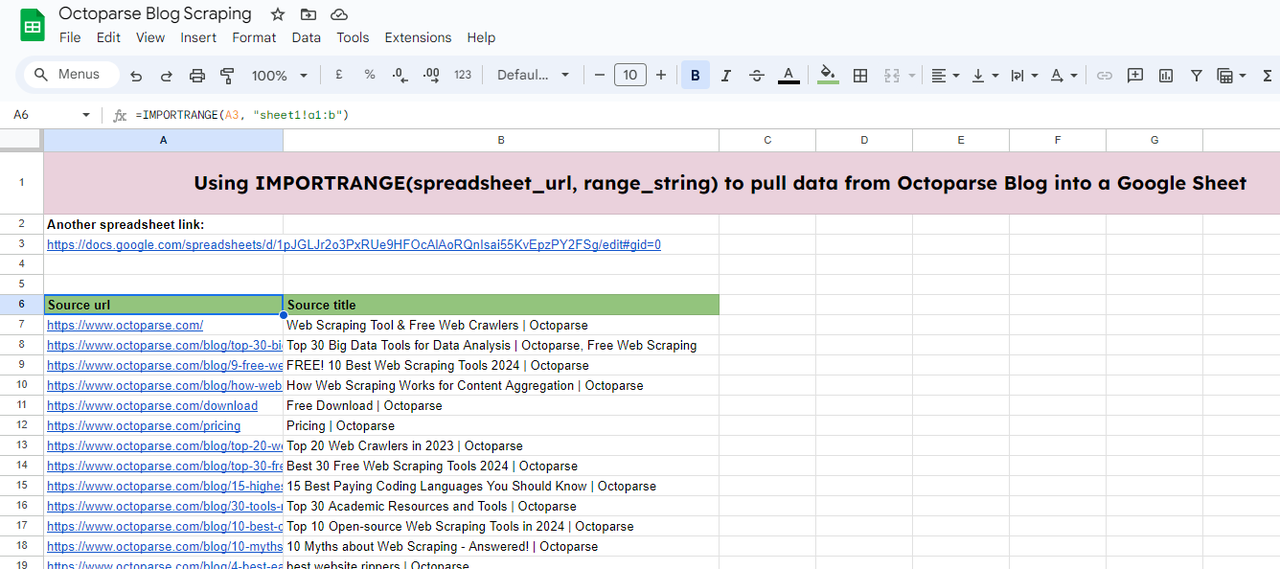
=IMPORTRANGE(spreadsheet_url, range_string)
- spreadsheet_url: L’URL del foglio di calcolo da cui vuoi importare i dati. Questo dovrebbe essere tra virgolette.
- range_string: Una stringa che specifica l’intervallo di celle da importare. Questo è tipicamente nel formato “SheetName!A1”.
In questo esempio, ho bisogno di importare dati da un altro foglio di calcolo (https://docs.google.com/spreadsheets/d/1pJGLJr2o3PxRUe9HFOcAlAoRQnIsai55KvEpzPY2FSg/edit#gid=0) a quello che sto modificando.
Per fare ciò, inserisci la funzione:
=IMPORTRANGE(A3, “sheet1!a1:b”)
- A3: è dove sono memorizzati i dati di origine.
- sheet1!a1: ho bisogno dei dati dal foglio1 del foglio di calcolo target. E l’intervallo dei dati è dalla cella A1 alla colonna B.
Poi, otterrai i dati dopo il caricamento.
Limitazioni di Fogli Google nel Web Scraping
Sebbene queste 5 funzioni semplifichino il nostro modo di importare dati dai siti web a Google Sheets, ci sono molte limitazioni.
Volume dei dati
Queste funzioni non possono importare grandi volumi di dati che coinvolgono la paginazione. Come puoi vedere nell’esempio di IMPORTXML, possiamo solo estrarre una pagina di dati. Se hai bisogno di tutte le pagine, dovrai farlo cambiando l’URL continuamente.
Contenuto dinamico
Le funzioni sopra menzionate possono solo estrarre dati statici e strutturati. Mentre i dati dinamici caricati con Javascript e AJAX sono fuori dalla loro portata.
Limiti di frequenza
Se richiedi i dati troppo frequentemente, potresti attivare il limite di frequenza di Google, impedendoti temporaneamente di estrarre ulteriori dati.
Manutenzione costante
Poiché alcune funzioni si basano sull’HTML del sito web per localizzare i dati, una volta che la struttura del sito cambia, i tuoi dati saranno influenzati e diventeranno invalidi.
Soluzione Automatizzata Tutto-in-Uno: Software di Web Scraping Senza Codice
Se hai bisogno di più di una semplice tabella o lista di dati e non vuoi gestire la scrittura di script, allora un software di web scraping senza codice come Octoparse potrebbe essere la tua soluzione perfetta.
Ci sono molti scraper pre-costruiti (all’interno di Octoparse) su Internet che soddisfano la maggior parte delle esigenze comuni delle nostre attività e vite.
Ad esempio:
https://www.octoparse.it/template/google-maps-contact-scraper
Ci sono molti altri scraper da esplorare. Visita: Modelli pre-costruiti di Octoparse.
Con pochi parametri e clic, puoi ottenere tutti i dati in una volta senza dover fare il noioso copia e incolla manuale.
Se hai un caso più complesso da estrarre, puoi utilizzare l’interfaccia di scraping personalizzata di Octoparse. Nell’interfaccia, puoi creare il tuo flusso di lavoro automatizzato (regole di scraping) nel modo in cui navighi nel sito web. Tutto ciò viene fatto tramite punti e clic e non è coinvolto alcun codice grazie alle funzionalità di auto-rilevamento.
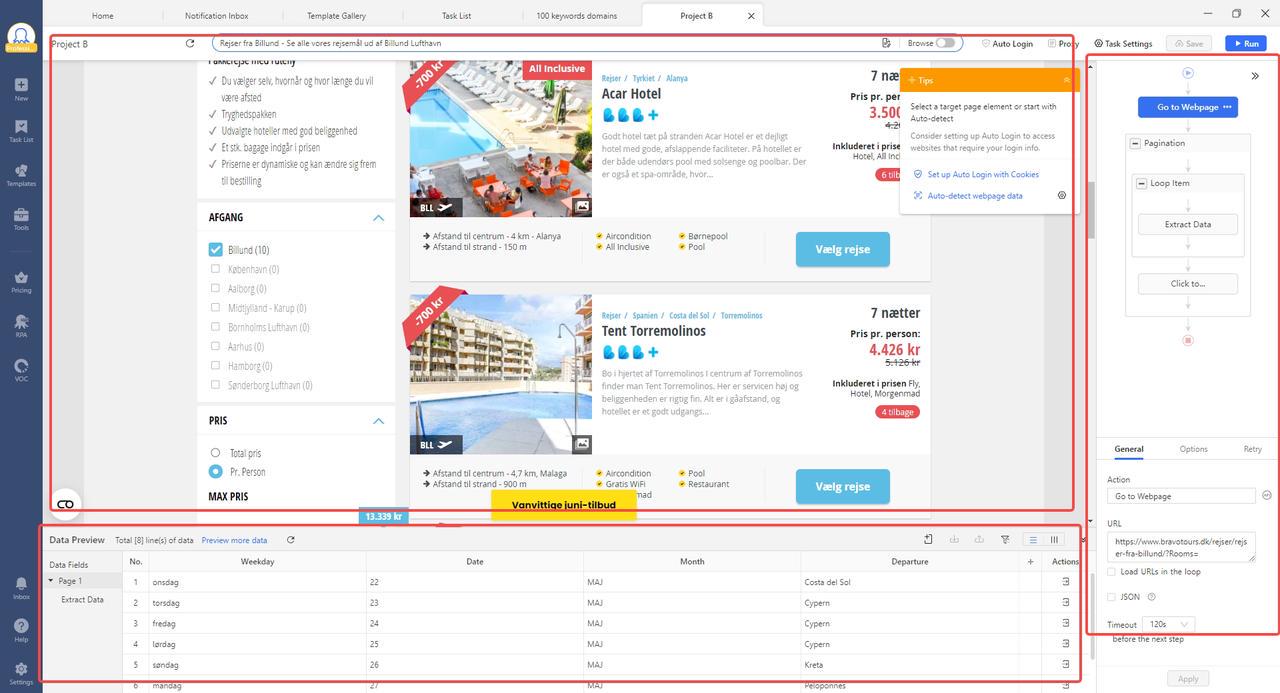
Altre Caratteristiche Che Puoi Ottenere dal Web Scraping Personalizzato:
- Servizio di scraper personalizzati e servizio di dati.
- Impostazioni anti-blocco: CAPTCHAs, rotazione IP, agenti utente, intervalli e login.
- Gestione di siti complessi: scorrimento infinito, menu a discesa, passaggio del mouse, retry, caricamento AJAX.
- Estrazione e archiviazione dati nel cloud.
- Piano gratuito e prova gratuita di 14 giorni per i piani Standard e Professional.
- Proxy residenziali a consumo; oltre 99 milioni di IP da 155 paesi.
- Team di supporto altamente reattivo: 24/7 tramite chat live su intercom.
- Integrazione con app di terze parti tramite Octoparse RPA; accesso API.
Consulta il Centro Assistenza di Octoparse se hai ancora domande sull’estrazione dei dati dai siti web. Se stai cercando un servizio dati per il tuo progetto, il servizio dati di Octoparse è una buona scelta. Lavoriamo a stretto contatto con te per capire le tue esigenze di dati e assicurarti di fornire ciò che desideri. Parla ora con un esperto di dati di Octoparse per discutere di come i servizi di web scraping possono aiutarti a massimizzare gli sforzi.



