Stai cercando come trovare immagini senza copyright su google senza scrivere codice? O forse hai bisogno di una soluzione basata su Python per raccogliere immagini su larga scala per l’addestramento dell’intelligenza artificiale?
Poiché Google non offre un’API ufficiale per la ricerca di immagini, lo scraping rimane il modo più efficace per raccogliere dati visivi in blocco. Octoparse esplorerà i cinque migliori strumenti di scraping che abbiamo testato nel 2026, offrendo approfondimenti chiari sui loro punti di forza e limiti.
Panoramica Rapida:
Uno scraper per Google Immagini estrae automaticamente dati chiave come URL delle immagini, testo alternativo, dimensioni e informazioni sulla pagina di origine dai risultati di ricerca. Ecco un’analisi dei migliori strumenti disponibili:
- Octoparse è la migliore opzione no-code per gli utenti senza background tecnico.
- Apify è perfetto per gli sviluppatori che hanno familiarità con le API.
- Python con Playwright è l’ideale per gli ingegneri che necessitano di un controllo completo e personalizzato.
- SerpAPI è ottimo per ottenere output JSON strutturati tramite API.
- Outscraper è il migliore per uno scraping rapido basato su cloud che non richiede configurazione.
Cos’è uno scraper per Google Immagini?
Uno scraper per Google Immagini è uno strumento che automatizza il processo di ricerca e scopre come trovare immagini senza copyright su google estraendo dati strutturati dai risultati, come URL delle immagini, testo alternativo, URL della pagina di origine, dimensioni dell’immagine e miniature.
Perché usare lo scraping invece di un’API ufficiale?
Google non offre un’API dedicata per la ricerca di immagini. La Custom Search JSON API, l’opzione ufficiale più vicina, limita i risultati delle immagini a 10 per query e addebita $5 per 1.000 query dopo il limite gratuito di 100 query. A partire dal 2025, i nuovi utenti non possono accedere a questa API e gli utenti esistenti dovranno passare a Vertex AI Search entro il 2027.
I web scraper, al contrario, interagiscono con Google Immagini come un browser, estraendo i risultati in formati strutturati (CSV, Excel, JSON).
Nel nostro test del 2026, estrarre 1.000 URL di immagini tramite la Custom Search API di Google sarebbe costato $4,50 e avrebbe richiesto nove cicli di fatturazione separati. Gli stessi 1.000 URL hanno richiesto 4 minuti e $0 su un altro scraper gratuito per immagini di Google.
È legale fare scraping su Google Images?
Negli Stati Uniti, lo scraping di dati accessibili al pubblico è generalmente legale, come chiarito dalla sentenza del 2022 hiQ Labs contro LinkedIn. Tuttavia, questo si applica solo al Computer Fraud and Abuse Act (CFAA) e non annulla altre considerazioni legali, come la legge sul copyright o i Termini di Servizio di un sito web.
Lo scraping dei metadati (ad es. URL, testo alternativo, dimensioni) è distinto dal download e dalla ridistribuzione dei file immagine. I file immagine sono solitamente protetti da copyright, quindi la ridistribuzione senza autorizzazione può violare la legge sul copyright.
Migliori Pratiche:
- Controlla sempre i Termini di Servizio e il file robots.txt di un sito web prima di effettuare lo scraping.
- Per uso commerciale, consulta un esperto legale per garantire la conformità alle leggi pertinenti. Questo articolo non costituisce consulenza legale.
Cosa puoi fare con le immagini estratte?
Quando scegli uno scraper per Google Immagini, considera questi casi d’uso comuni:
- Dataset per IA e Machine Learning: I ricercatori creano grandi dataset etichettati per modelli di intelligenza artificiale, accelerando il processo rispetto alla raccolta manuale.
- Monitoraggio Visivo dei Competitor: I brand tracciano le immagini dei prodotti della concorrenza per migliorare la loro strategia visiva in e-commerce, moda e beni di consumo.
- Ricerche di Mercato: Lo scraping dei risultati delle immagini aiuta le aziende a individuare le tendenze in fatto di packaging, colori e formati dei prodotti.
- Raccolta Prodotti E-commerce: I rivenditori necessitano di web scraping per l’e-commerce per cataloghi e siti di comparazione prezzi.
- Ricerca Accademica: I ricercatori risparmiano tempo sui download manuali effettuando lo scraping di immagini per analisi visive su larga scala.
I 5 migliori scraper per Google Images
⭐ Come Abbiamo Testato ⭐ Abbiamo testato ogni strumento utilizzando tre parole chiave: “design del packaging del prodotto”, “design di uffici moderni” e “razze di gatti”. La nostra valutazione si è concentrata sui seguenti fattori chiave:
- Tempo di Configurazione: Tempo dalla registrazione alla prima esportazione.
- Recupero Immagini: Numero di immagini estratte in 10 minuti.
- Modalità di Errore: Eventuali problemi riscontrati durante i test.
Abbiamo anche valutato gli strumenti in base a cinque criteri:
- Complessità di configurazione
- Gestione del rendering dinamico JavaScript
- Qualità dei dati (metadati completi rispetto ai soli file immagine)
- Esecuzione in cloud e supporto per la pianificazione
- Trasparenza dei prezzi
1. Octoparse: il miglior scraper no-code per Google Immagini
Ideale per: Utenti non tecnici, esperti di marketing, creatori di dataset per IA, ricercatori accademici
Octoparse è una piattaforma di web scraping senza codice che consente agli utenti di creare uno scraper per Google Immagini in meno di cinque minuti utilizzando un modello di web scraping predefinito di Octoparse.
Puoi eseguirlo in due modi: direttamente nel tuo browser tramite l’app web di Octoparse, oppure scaricare Octoparse su Windows e Mac. Entrambe le opzioni utilizzano lo stesso template e producono risultati identici.
La sua funzione di rilevamento automatico basata sull’IA analizza la struttura della pagina e identifica automaticamente i campi dati necessari. Le esportazioni sono disponibili in CSV, Excel, Google Sheets o tramite API.
⭐ Risultati del Test: Nel nostro test, il template di Octoparse per Google Immagini ha restituito 459 righe di immagini in 21 minuti e 42 secondi per la query “cane carino”, eseguito su 20 nodi cloud con zero trigger CAPTCHA. Il CSV esportato conteneva nove colonne:
- Query, Title, Title_URL, Source, Full_image, Full_image_size, Thumbnail_image, Thumbnail_width, Thumbnail_height.
Caratteristiche Chiave:
- Supporto Rendering Dinamico: Gestisce lo scorrimento infinito e le immagini caricate in modo lento (lazy-loaded) con il suo motore browser integrato.
- Modalità Cloud: Esegue gli scraper sui server di Octoparse per operazioni 24/7, risparmiando risorse locali.
- Template Predefiniti: Template gratuito per lo scraping di Google Immagini. Inserisci una parola chiave, scegli la modalità locale o cloud ed esporta i risultati. Supporta fino a 10.000 parole chiave per l’elaborazione in batch.
- Output Completo: Estrae l’URL completo dell’immagine, la miniatura, il testo alternativo, la fonte e le dimensioni in un’unica esecuzione.
- Accesso Proxy Opzionale: Instrada gli scraper tramite IP a rotazione per grandi lotti o regioni soggette a restrizioni.
| Pro | Contro |
| ✅ Nessuna codifica richiesta e funziona sia nel browser che nel client desktop, nessuna installazione necessaria ✅ Rilevamento automatico dell’IA per URL dell’immagine, testo alternativo, fonte e dimensioni ✅ Gestisce le pagine dinamiche e lo scorrimento infinito in modo nativo ✅ Pianificazione basata su cloud con scraping 24/7 ✅ Conforme a GDPR e CCPA ✅ Template predefiniti per una configurazione più rapida ✅ L’elaborazione in batch supporta fino a 10.000 parole chiave per attività | ❌ Lo scraping in cloud consuma i crediti del piano ❌ Le attività di scraping più grandi potrebbero essere più lente rispetto agli strumenti API-first |
- Piano gratuito disponibile (scraping locale, esecuzioni cloud limitate)
- I piani a pagamento partono da $69/mese, con una garanzia di rimborso di 5 giorni su tutti i piani a pagamento.
Cosa dicono gli utenti su Trustpilot:
Ho scoperto Octoparse mentre cercavo un modo migliore per estrarre grandi quantità di dati web. Dopo aver provato metodi manuali e strumenti di base, Octoparse si è distinto come l’opzione più potente e che fa risparmiare tempo. È preciso, flessibile e facile da usare, anche per progetti piccoli o personali. Anche il team di supporto è stato incredibilmente reattivo.
Limiti Onesti:
Octoparse è ottimo per estrarre metadati strutturati come URL e testo alternativo, ma non è adatto per attività di manipolazione delle immagini (ad es. ridimensionamento o classificazione). Per queste sarebbero necessari strumenti aggiuntivi. Lavori in batch più pesanti (migliaia di parole chiave) richiedono un piano a pagamento per i nodi cloud, poiché il piano gratuito supporta solo esecuzioni locali a thread singolo.
Il Nostro Verdetto: Per lo scraping regolare di Google Immagini senza programmazione, Octoparse è la soluzione più pratica nel 2026. Il suo rilevamento dei campi basato sull’IA e la pianificazione in cloud lo rendono ideale per gli utenti non tecnici, risparmiando tempo su configurazione e impostazione.
👉 Inizia una prova gratuita di Octoparse | Sfoglia i modelli di scraping per Google Immagini
https://www.octoparse.it/template/google-image-scraper
2. Apify: il migliore per sviluppatori e workflow API
Ideale per: Sviluppatori che necessitano di integrazione API e che hanno familiarità con piattaforme basate su “Actor”.
Lo scraper per Google Immagini di Apify è un “Actor” (attività di scraping containerizzata) creato dalla community sulla loro piattaforma cloud. Estrae URL delle immagini, testo alternativo, titoli, dimensioni, URL delle miniature e dati della pagina di origine, esportando in formato JSON, CSV, Excel o HTML.
⭐ Risultati del Test
Nel nostro test, lo scraper di Apify ha estratto 500 immagini in 2 minuti e 40 secondi, utilizzando circa 0,14 Compute Units (CU). Alla tariffa del piano Scale di $0,25 per CU, questo costa circa $0,035 per 500 immagini (esclusi gli addebiti per evento stabiliti dal manutentore dell’Actor).
Apify utilizza un modello di prezzo pay-per-event, addebitando in base ai risultati delle immagini restituiti. Il piano gratuito include $5 in crediti mensili, sufficienti per estrazioni di piccole e medie dimensioni.
Punti di Forza per gli Sviluppatori:
- Integrazione API: Attiva le esecuzioni dello scraper a livello di codice tramite API REST.
- Concatenamento di Actor: Collegati ad altri Actor, come “Download Images From Dataset”, per scaricare file immagine in blocco.
- Integrazione di Servizi Cloud: Connettiti con altri servizi cloud tramite webhook.
| Pro | Contro |
| ✅ API flessibile per il controllo programmatico ✅ Può essere concatenato con altri Actor per funzionalità estese ✅ Scalabile tramite webhook e integrazioni cloud ✅ Supporta formati di output multipli (JSON, CSV, Excel, HTML) | ❌ Richiede la conoscenza del modello Actor di Apify e delle Compute Units ❌ Non adatto a utenti non tecnici a causa della complessità ❌ Actor creato dalla community, l’affidabilità dipende dai singoli sviluppatori |
Prezzi:
- Piano gratuito con $5 in crediti mensili
- Prezzi pay-per-event basati sull’estrazione per immagine, con dettagli completi sui prezzi disponibili sulla pagina dei prezzi di Apify.
Cosa dicono gli utenti su Trustpilot:
Il punto di attrito più grande è la curva di apprendimento, come comprendere le compute units, navigare nei prezzi specifici per actor e prendere confidenza con la dashboard: tutto richiede tempo reale all’inizio.
Limiti Onesti: Apify è ottimo per gli sviluppatori, ma il modello Actor e l’integrazione API potrebbero essere difficili per gli utenti non tecnici. Poiché lo scraper per Google Immagini è un Actor creato dalla community, la sua manutenzione e affidabilità dipendono dal singolo sviluppatore, non da Apify stesso.
Il Nostro Verdetto: Se hai risorse tecniche o sei uno sviluppatore, Apify offre forte flessibilità e scalabilità attraverso la sua API e le integrazioni cloud. Tuttavia, non è l’opzione migliore per gli utenti non tecnici che cercano una soluzione più semplice e senza codice.
3. Python + Playwright (o Selenium): Il Migliore per Ingegneri che Necessitano di Controllo Completo
Ideale per: Ingegneri del software che necessitano di un maggiore controllo sul processo di scraping quando gli strumenti pronti all’uso sono troppo limitanti.
L’utilizzo di Python con Playwright (o Selenium) fornisce agli ingegneri un controllo completo, ideale per soluzioni personalizzate come logiche di impaginazione specifiche, filtraggio della risoluzione o integrazione con pipeline ML. Entrambe le librerie sono gratuite e open-source.
⭐ Risultati del Test: Nel nostro test, uno script di base di Playwright ha estratto 180 URL di immagini prima di attivare un limitatore di velocità alla richiesta 85. Utilizzando un proxy residenziale ($8/GB), abbiamo esteso la sessione a oltre 600 URL. Il tempo di configurazione per uno sviluppatore alle prime armi con Playwright è stato di circa 30 minuti, inclusa l’installazione di Chromium e l’ispezione dei selettori.
Come Funziona:
- Avvia un browser headless.
- Naviga su Google Immagini con la tua query di ricerca.
- Attendi il caricamento dei contenuti dinamici.
- Estrai i tag
imge i metadati associati (URL, testo alternativo, ecc.).
Perché Playwright rispetto a Selenium nel 2026? Playwright è generalmente preferito a Selenium per il suo supporto asincrono e un rilevamento degli elementi più affidabile, rendendolo una scelta più stabile per il 2026.
⚠️ Due insidie comuni con questo approccio:
- Frequenti modifiche al frontend: La struttura HTML di Google si aggiorna spesso, interrompendo selettori come img.YQ4gaf. Ispeziona sempre prima la pagina.
- Miniature Base64: L’attributo
srcrestituisce spesso miniature in base64 invece di URL completi. Clicca su ogni risultato per estrarre l’URL completo.
| Pro | Contro |
| ✅ Controllo completo sulla logica di scraping ✅ Gratuito, open-source ✅ Personalizzabile per esigenze complesse ✅ Ideale per l’integrazione di pipeline | ❌ Elevata manutenzione a causa del cambiamento dei selettori CSS ❌ Vulnerabile al rilevamento (browser headless, CAPTCHA) ❌ Sforzo ingegneristico continuo per l’affidabilità |
Limiti Onesti: Sebbene Python + Playwright (o Selenium) sia potente, le frequenti modifiche HTML e gli ostacoli al rilevamento lo rendono meno pratico su larga scala. Per attività ricorrenti, gli strumenti gestiti sono spesso più affidabili ed economici.
Il Nostro Verdetto: Ottimo per progetti una tantum o team con risorse ingegneristiche. Per i flussi di lavoro ricorrenti, gli strumenti gestiti possono offrire un valore a lungo termine migliore.
4. SerpAPI: il migliore per output JSON puliti tramite API
Ideale per: Sviluppatori che necessitano di dati di Google Immagini in formato JSON strutturato senza gestire un browser.
SerpAPI fornisce un’API per i risultati dei motori di ricerca con un endpoint dedicato per Google Immagini. Con una singola richiesta HTTP, puoi recuperare dati JSON strutturati, aggirando la necessità di automazione del browser, analisi HTML o gestione dei selettori. Gestisce la rotazione dei proxy, la risoluzione dei CAPTCHA e il rendering.
⭐ Risultati del Test:
- 1 richiesta ha restituito 100 risultati di immagini in 1,3 secondi.
- Tempo di risposta mediano su 20 richieste: 2,4 secondi.
- $75/mese per 5.000 ricerche (~$0,015 per query).
- Dati restituiti: URL originali delle immagini/URL delle miniature/Titoli/Domini di origine/Dimensioni delle immagini
| Pro | Contro |
| ✅ Output JSON pulito e strutturato con configurazione minima ✅ Gestione automatica di proxy, CAPTCHA e rendering ✅ Facile integrazione con Python, Node.js, ecc. ✅ Scalabile per l’uso in produzione ✅ Scudo Legale USA sui piani di livello superiore (fino a $2M) | ❌ Nessun piano gratuito (parte da $75/mese) ❌ Metadati limitati (nessun contenuto della pagina circostante) ❌ Meno conveniente per ricerche una tantum |
Cosa dicono gli utenti su G2:
Il modello di credito “usalo o perdilo” è spesso criticato, poiché le ricerche non utilizzate non si accumulano, il che aumenta i costi effettivi per progetti a volume variabile.
Limiti Onesti: SerpAPI è perfetto per l’estrazione di dati strutturati ma manca dei dati contestuali completi forniti dagli scraper full-page. I suoi prezzi potrebbero non essere ideali per un uso occasionale.
⚠️ Nota Legale:
Nel dicembre 2025, Google ha intentato una causa DMCA contro SerpAPI per aver aggirato il sistema anti-scraping di Google. Il caso è in corso, con un’udienza prevista per maggio 2026. Prevedi un provider di backup in produzione.
Il Nostro Verdetto: SerpAPI è ottimo per gli sviluppatori che necessitano di dati strutturati e affidabili da Google Immagini. Tuttavia, la mancanza di un piano gratuito e la causa legale in corso potrebbero renderlo meno adatto per utenti occasionali o per coloro che necessitano dell’affidabilità di un singolo fornitore.
👉 Esplora l’API di SerpAPI per Google Immagini | Scopri i dettagli sui prezzi
5. Outscraper: il migliore per attività rapide basate su cloud senza configurazione
Ideale per: Utenti che necessitano di un semplice scraper per Google Immagini basato su browser senza installazione.
Outscraper fornisce uno scraper per Google Immagini basato su cloud che non richiede installazione. Basta registrarsi, inserire le parole chiave e scaricare i risultati in formato CSV o Excel. È disponibile un livello gratuito con crediti limitati.
⭐ Risultati del Test:
- I crediti del livello gratuito hanno coperto circa tre esecuzioni da 50 immagini ciascuna.
- Tempo di configurazione: Meno di 2 minuti per la prima esportazione.
- Tempo di estrazione: 35 secondi per 50 immagini.
- Dati restituiti: URL delle immagini/URL delle pagine di origine/Titoli delle immagini/Link alle miniature
Nota: Outscraper non estrae il testo alternativo in modo strutturato come Octoparse o Apify, il che potrebbe limitarne l’uso per dataset di addestramento IA.
| Pro | Contro |
| ✅ Nessuna installazione richiesta, funziona nel cloud ✅ Interfaccia semplice per scraping rapidi e una tantum ✅ Esporta in CSV o Excel ✅ Livello gratuito disponibile per un utilizzo limitato ✅ Ideale per l’estrazione occasionale di immagini | ❌ Flessibilità limitata per attività di scraping complesse (ad es. nessun builder visivo, pianificazione limitata) ❌ Nessuna libreria di template preconfigurata ❌ Non ideale per scraping ricorrenti o con più parole chiave ❌ Estrazione del testo alternativo incoerente rispetto ad altri strumenti |
Limiti Onesti: Outscraper funziona bene per attività una tantum ma manca di funzionalità avanzate come un builder visivo e una pianificazione complessa, rendendolo inadatto per esigenze di scraping continue.
Il Nostro Verdetto: Per uno scraping rapido basato su cloud senza installazione richiesta, Outscraper è un’ottima scelta. Tuttavia, per scraping più complessi o ricorrenti, strumenti come Octoparse o Apify offrono maggiori funzionalità e flessibilità.
👉 Inizia con Outscraper | Esplora i piani disponibili
⭐ Menzioni d’Onore
Sebbene i cinque strumenti sopra coprano la maggior parte dei casi d’uso, eccone alcuni altri da prendere in considerazione nel 2026:
- API per Scraper di Google Immagini di ScrapingBee: Restituisce URL di immagini strutturati, metadati e testo alternativo. Prezzi a partire da $49/mese. Ideale per gli sviluppatori che necessitano di un semplice endpoint HTTP senza un’ampia copertura sui motori di ricerca.
- ScraperAPI: Un’API di scraping generica con supporto per Google Immagini tramite il suo endpoint SERP. Parte da $49/mese per 100.000 crediti. Ottimo per i team che già utilizzano ScraperAPI per altre fonti di dati.
- API per Google Immagini di Scrapingdog: Una nuova opzione con prezzi per richiesta a partire da $0,001 per query. Documentazione meno matura rispetto a SerpAPI ma più conveniente per volumi elevati.
Vale la pena esplorare queste opzioni se le tue esigenze non si allineano con i primi cinque strumenti menzionati in precedenza.
Tabella Comparativa degli Scraper per Google Immagini
| Strumento | Ideale Per | Tempo di Configurazione | Rendering JS | Prezzo di Partenza | Opzione Gratuita | Acquisizione Testo Alternativo |
| Octoparse | Non programmatori, esecuzioni programmate | 5 min (template) | ✅ Nativo | $69/mese | ✅ Piano gratuito (locale) | ✅ Sì |
| Apify | Sviluppatori, flussi di lavoro API | 10 min + chiave API | ✅ Gestito | $29/mese + per-evento | ✅ $5/mese crediti | ✅ Sì |
| Python + Playwright | Ingegneri, logica personalizzata | 30+ min | Manuale | Gratuito (librerie) | ✅ Completamente gratuito | ✅ Se codificato |
| SerpAPI | JSON pulito, produzione | Meno di 5 min | ✅ Gestito | $75/mese per 5K query | Limitato (100/mese) | Parziale |
| Outscraper | Lavori una tantum, nessuna installazione | 2 min | ✅ Gestito | Pay-as-you-go | ✅ Crediti limitati | ⚠️ Incoerente |
Guida Passo Passo su Come Fare Scraping su Google Immagini
Il modo più veloce per estrarre immagini da Google con Octoparse è utilizzare il template predefinito Google Image Scraper. Non è richiesta alcuna configurazione o impostazione dei selettori. Basta inserire la parola chiave e avviare.
Passo 1: apri il modello
- Web: Visita octoparse.it/template/google-image-scraper, accedi o crea un account e clicca su Try it!
https://www.octoparse.it/template/google-image-scraper
- Desktop: Apri Octoparse, vai su Modelli > cerca “Google image” > seleziona il modello.
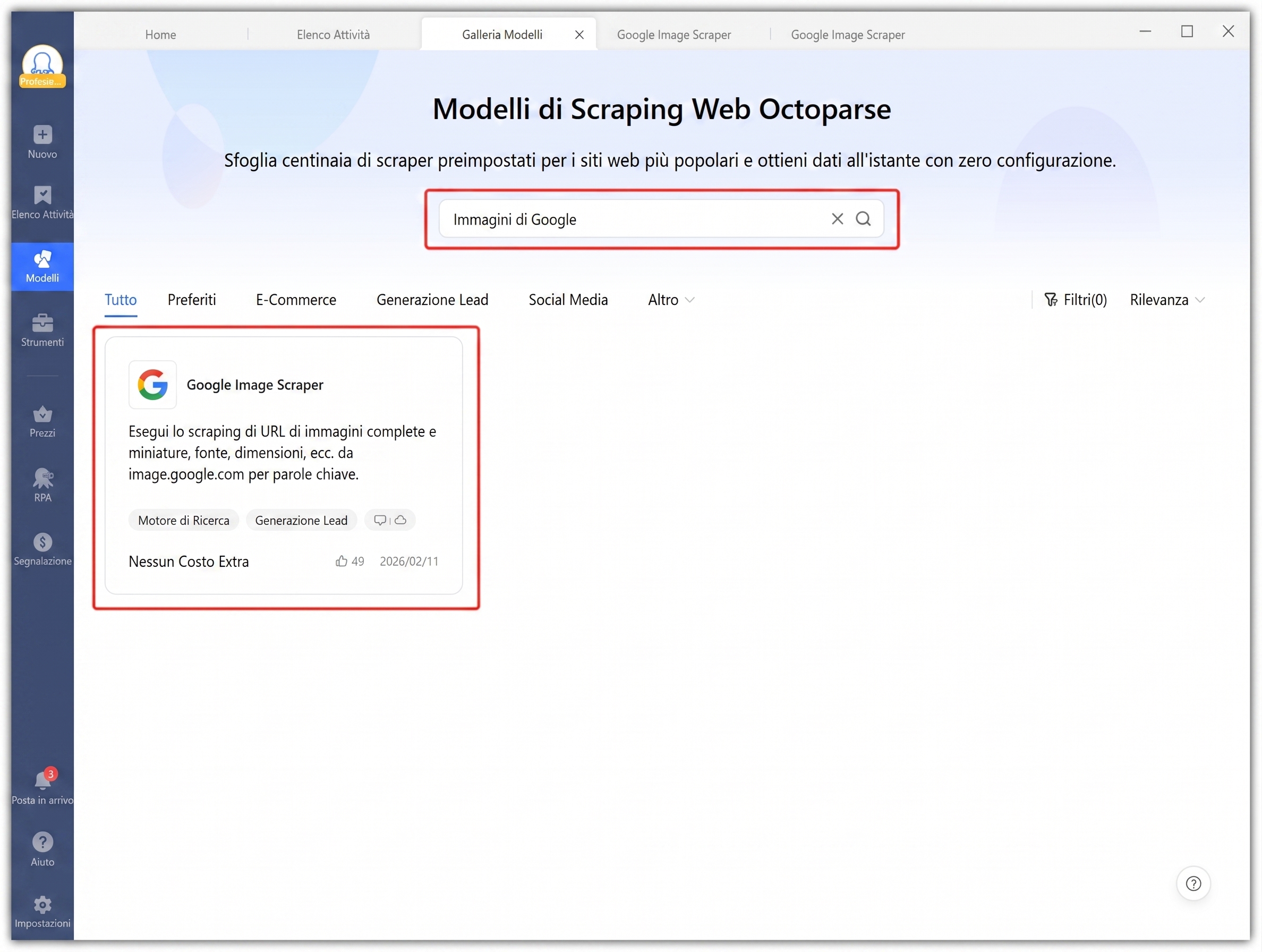
Passo 2: Inserisci la tua parola chiave da cercare
Il pannello di Input accetta fino a 10.000 parole chiave. Hai due opzioni:
- Inserimento manuale: Digita una parola chiave per riga (ad es. “cane carino” o “design del packaging del prodotto”).
- Importazione file: Carica un file TXT o CSV con parole chiave per grandi lotti.
- Opzionale: Seleziona “Access websites via proxies” per ruotare gli IP ed evitare blocchi.
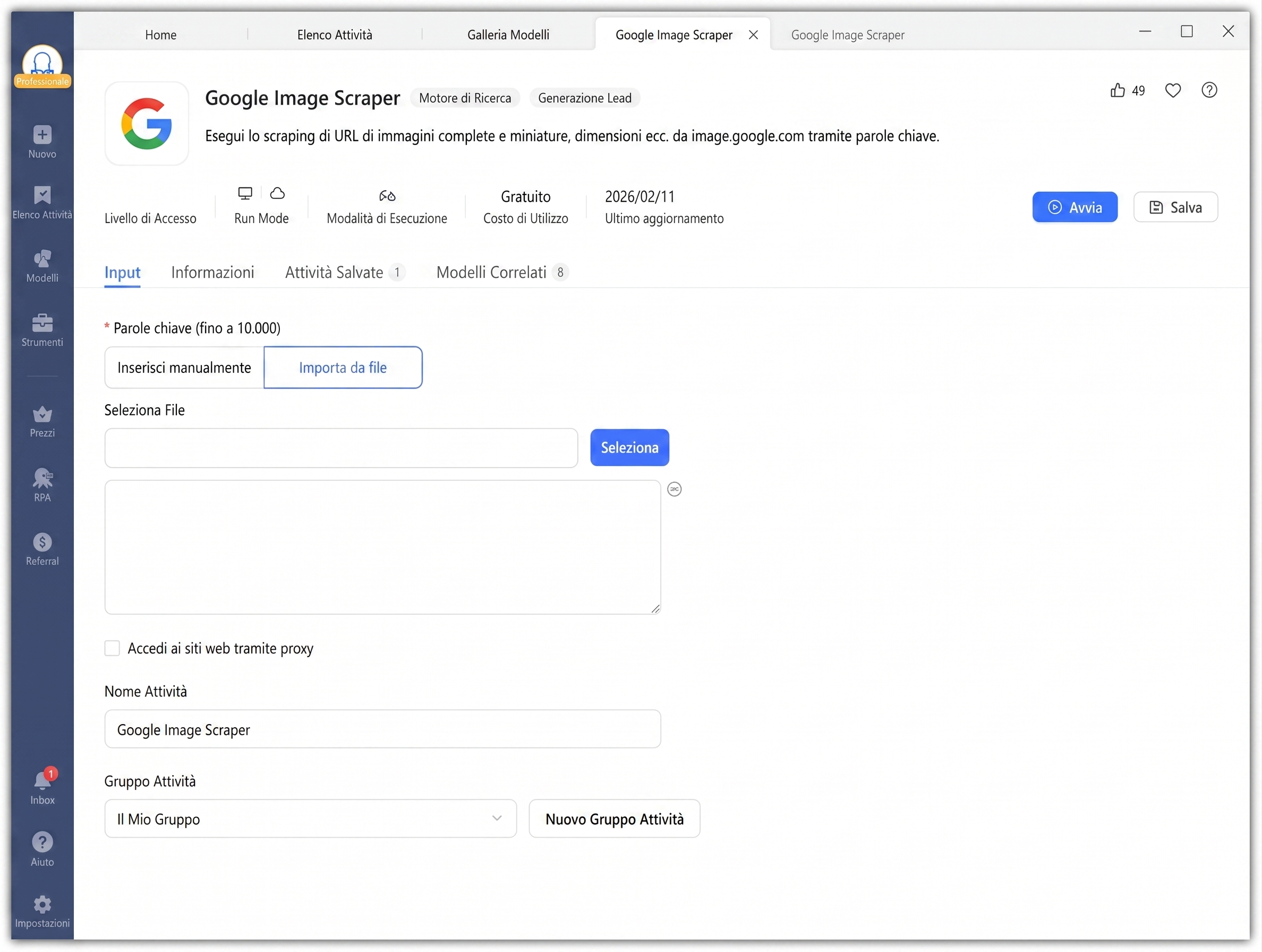
Passo 3: Configura le Impostazioni dell’Attività (Opzionale)
Scorri verso il basso fino alla sezione Task Setting per rinominare l’attività o assegnarla a un gruppo. Le impostazioni predefinite funzionano bene per la maggior parte dei casi d’uso.
Passo 4: Esegui l’Attività
Clicca su Start e scegli la modalità di esecuzione:
- Esegui sul Web / Esegui Localmente: Funziona sulla tua macchina (ottimo per piccole attività).
- Esegui in Cloud: Funziona sui server di Octoparse, consente attività pianificate, consuma i crediti del piano.
Passo 5: Monitora l’Esecuzione
Tieni traccia dei progressi tramite la pagina Task Info: stato, conteggio dei dati, tempo trascorso, nodi cloud utilizzati e CAPTCHA incontrati.
Passo 6: Esporta i Tuoi Dati
Una volta completato, clicca su Export Data e scegli il tuo formato: CSV, Excel, Google Sheets o JSON tramite API. I dati includono 9 colonne come URL delle immagini e testo alternativo.
👉 Sfoglia la Libreria dei Template di Octoparse Hai bisogno di estrarre dati da altre proprietà di Google? Octoparse ha template per l’intero ecosistema Google:
- Scraper di Google Maps: nomi di aziende, indirizzi, valutazioni, recensioni, numeri di telefono e molto altro per la lead generation e la SEO locale.
https://www.octoparse.it/template/google-maps-advanced-scraper
- Trova Email di Google Maps: email di contatto estratte dagli elenchi di Google Maps, al prezzo di $0,5 per 1.000 righe.
https://www.octoparse.it/template/google-maps-contact-scraper
Per gli sviluppatori che desiderano estrarre immagini utilizzando Python, consulta la nostra guida completa su come estrarre dati usando Python.
Sfide comuni durante lo scraping di Google Immagini (e come risolverle)
Sfida 1: Blocchi IP e CAPTCHA
Google blocca gli IP dopo troppe richieste in un breve periodo di tempo.
Soluzione:
- Utilizza scraper basati su cloud come Octoparse, Apify o Outscraper per la rotazione automatica dei proxy.
- Per gli script Python, integra proxy residenziali e aggiungi ritardi (ad es. 1,5–4 secondi) per imitare il comportamento umano.
Sfida 2: I Selettori CSS di Google Cambiano Senza Preavviso
Se stai utilizzando uno scraper Python fai-da-te, l’estrazione basata sui selettori si interrompe silenziosamente ogni volta che Google rilascia un aggiornamento del frontend. Questi aggiornamenti si verificano più volte all’anno e il tuo script restituirà risultati vuoti senza preavviso.
Soluzione:
- Usa scraper visivi senza codice o servizi API-first:
- Octoparse si adatta alla struttura della pagina con un motore di rendering invece di fare affidamento su selettori statici.
- L’Actor di Apify mantiene selettori aggiornati per stare al passo con le modifiche di Google.
- Per Python, convalida che i risultati vengano restituiti e imposta avvisi se lo scraper non produce nulla.
Sfida 3: Fingerprinting del Browser Headless
Google rileva i browser Chromium headless utilizzando proprietà come navigator.webdriver = true, plugin mancanti e comportamento incoerente del viewport. Le sessioni headless vengono bloccate più velocemente di quelle normali.
Soluzione:
- Usa la modalità stealth di Playwright per impostare navigator.webdriver=false, rendendo più difficile il rilevamento.
- Usa dimensioni del viewport realistiche e una stringa user agent plausibile.
- Le piattaforme cloud come Octoparse gestiscono questo in modo invisibile, riducendo i rischi di rilevamento rispetto agli script fai-da-te.
Sfida 4: Copyright e Diritti di Utilizzo delle Immagini
Mentre lo scraping può fornirti metadati utili, le immagini sono spesso protette da copyright. Capire come trovare immagini senza copyright su google è essenziale, poiché il download e la ridistribuzione di immagini senza licenza possono portare a problemi legali.
Soluzione:
- Concentrati sulla raccolta di URL di immagini e metadati invece di scaricare i file immagine per ricerche o dataset di addestramento IA.
- Usa il filtro dei diritti di utilizzo di Google per i contenuti pubblicati:
- Per le immagini con licenza Creative Commons, usa questo formato di URL di ricerca:
- https://images.google.com/search?q=your+query&tbm=isch&tbs=il:cl
- Il parametro
tbs=il:clfiltra le immagini con licenza Creative Commons. - Aggiungi
&tbs=il:olper ottenere immagini che consentono l’uso commerciale.
Domande Frequenti
È legale fare scraping su Google Immagini? Negli Stati Uniti, lo scraping di dati accessibili al pubblico è generalmente legale in base alla sentenza hiQ v. LinkedIn (2022), la quale ha chiarito che lo scraping non viola il Computer Fraud and Abuse Act (CFAA). Tuttavia, questo non annulla la legge sul copyright, i Termini di Servizio del sito web o le rivendicazioni statali.
Per Google Immagini, lo scraping dei metadati (ad es. URL, testo alternativo, dimensioni) è distinto dal download dei file immagine. Poiché le immagini sono in genere protette da copyright, la ridistribuzione o l’uso commerciale senza autorizzazione può comunque portare a problemi legali.
Google ha un’API ufficiale per la ricerca di immagini?
No. La Custom Search JSON API di Google supporta la ricerca di immagini ma limita le risposte a 10 risultati per query e non è adatta per l’estrazione in blocco. L’API di Google Foto funziona solo con librerie personali, non per la ricerca di immagini generica. Per la raccolta di immagini in blocco, gli strumenti di web scraping sono più pratici.
Come faccio a fare scraping su Google Immagini senza Python?
Usa uno strumento senza codice come Octoparse. Apri il template Google Image Scraper nel browser o nell’app desktop, inserisci la tua parola chiave di ricerca, lascia che il template faccia il resto, quindi esporta in CSV o Google Sheets. Non è richiesta alcuna conoscenza di programmazione.
Quali dati posso estrarre da Google Immagini?
Uno scraper per Google Immagini può raccogliere:
- URL dell’immagine: Link diretto al file immagine
- URL della miniatura: Versione di anteprima
- Testo alternativo: Testo descrittivo
- URL della pagina di origine: Dove è stata trovata l’immagine
- Titolo dell’immagine: L’attributo title dell’immagine
- Dimensioni dell’immagine: Larghezza e altezza in pixel
Controlla l’output del tuo strumento per assicurarti che catturi i dati di cui hai bisogno.
Come scarico immagini in blocco da Google Immagini?
Lo scraping fornisce gli URL delle immagini, ma il download delle immagini vere e proprie è un passaggio separato:
- In Octoparse, esporta l’elenco degli URL in CSV, quindi utilizza uno strumento di download in batch o uno script Python.
- In Apify, concatena l’Actor Google Images Scraper con l’Actor “Download Images From Dataset” per l’automazione.
- Per gli utenti Python, aggiungi un ciclo
requests.get(image_url)dopo lo scraping per scaricare ogni immagine.
Quale scraper per Google Immagini è gratuito?
Diversi strumenti offrono livelli gratuiti. Il piano gratuito di Octoparse include il template Google Image Scraper con un massimo di 50.000 righe al mese su esecuzioni locali. Il piano gratuito di Apify fornisce $5 in crediti mensili, sufficienti per centinaia di piccole estrazioni. Python con Playwright è completamente gratuito da eseguire, sebbene i proxy residenziali ($8–$15/GB nel 2026) siano necessari per grandi volumi. Outscraper offre crediti gratuiti limitati. SerpAPI offre un livello gratuito per i test ma richiede un piano a pagamento a partire da $75/mese per l’uso in produzione.
Conclusione
Scegliere il giusto scraper per Google Immagini dipende dalle tue esigenze. Per gli utenti non tecnici, Octoparse offre una soluzione semplice e senza codice. Gli sviluppatori che necessitano di un maggiore controllo possono optare per Apify o Python con Playwright, sebbene quest’ultimo richieda più manutenzione. Se stai cercando uno strumento semplice basato su cloud senza installazione, Outscraper è una solida opzione per attività rapide. In definitiva, seleziona uno strumento in base alla frequenza di utilizzo, alle esigenze di personalizzazione e alle competenze tecniche.